普通的论文阅读笔记
SORT3D: Spatial Object-centric Reasoning Toolbox for Zero-Shot 3D Grounding Using Large Language Models
| 期刊: |
| 分区: |
| 作者: Nader Zantout; Haochen Zhang; Pujith Kachana; Jinkai Qiu; Ji Zhang; Wenshan Wang |
| **论文发表日期: **2025-04-25 |
| **笔记创建日期: **2025/7/8 21:56:41 |
| **原文链接: **Zantout 等 - 2025 - SORT3D Spatial Object-centric Reasoning Toolbox for Zero-Shot 3D Grounding Using Large Language Mod.pdf |
| **摘要: **Interpreting object-referential language and grounding objects in 3D with spatial relations and attributes is essential for robots operating alongside humans. However, this task is often challenging due to the diversity of scenes, large number of fine-grained objects, and complex free-form nature of language references. Furthermore, in the 3D domain, obtaining large amounts of natural language training data is difficult. Thus, it is important for methods to learn from little data and zero-shot generalize to new environments. To address these challenges, we propose SORT3D, an approach that utilizes rich object attributes from 2D data and merges a heuristics-based spatial reasoning toolbox with the ability of large language models (LLMs) to perform sequential reasoning. Importantly, our method does not require text-to-3D data for training and can be applied zero-shot to unseen environments. We show that SORT3D achieves state-of-the-art performance on complex view-dependent grounding tasks on two benchmarks. We also implement the pipeline to run real-time on an autonomous vehicle and demonstrate that our approach can be used for object-goal navigation on previously unseen real-world environments. All source code for the system pipeline is publicly released at https://github.com/nzantout/SORT3D . |
| 理解对象指代语言并在三维空间中通过空间关系和属性将物体具体化(Grounding),对于在人类身边操作的机器人至关重要。然而,由于场景的多样性、海量的细粒度物体以及语言指代本身的复杂自由形式本质,这项任务通常具有挑战性。此外,在三维领域,获取大量自然语言训练数据十分困难。因此,方法需要具备</span></span>小样本学习和零样本泛化到新环境的能力就显得尤为重要。为应对这些挑战,我们提出了 SORT3D 方法。该方法利用来自二维数据的丰富物体属性,并将一个基于启发式的空间推理工具箱与大语言模型 (LLM) 执行序列推理的能力相结合。重要的是,我们的方法无需文本到三维数据的训练即可应用,并且能够零样本应用于未见过的环境。我们证明,SORT3D 在两个基准测试上针对复杂的视角依赖的具体化任务实现了最先进的性能。我们还将该管道实现在一辆自动驾驶车辆上实时运行,并证明我们的方法可用于在先前未见过的真实世界环境中进行以物体为目标的导航。系统的所有源代码已在 https://github.com/nzantout/SORT3D 公开。 |
💡创新点
本文解决了什么新的科学问题?
● 在缺少预训练的情况下如何结合vlm执行导航任务
提出了什么新的研究思路?
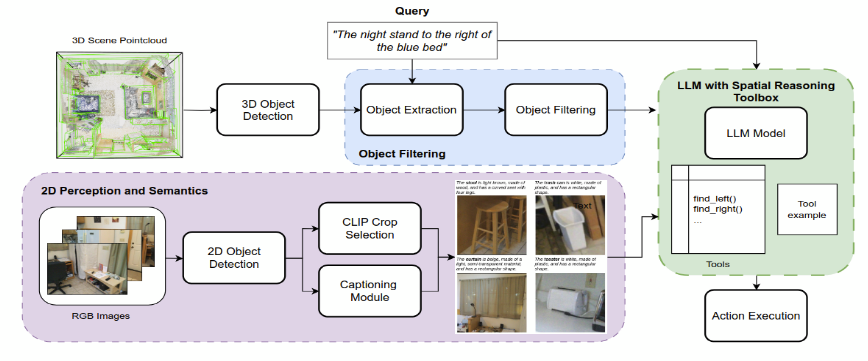
● 4个核心组件:1.三维场景感知(包含融合物体二维语义信息的处理管道)
2.基于输入语句的相关物体筛选
3.基于大语言模型(LLM)的空间推理
4.面向下游动作执行的代码生成

应用了什么新的研究工具?
●推出SORT3D,一种基于大语言模型的三维空间物体推理工具箱,为以物体为目标的导航定制的新颖三维空间推理流程
📚前言及文献综述
本研究的必要性、紧迫性、可行性是什么?
● 必要性:三维视觉语义具象化(3DVG)的困难性:
1.室内环境有众多属于细粒度类别(fine-grained)的物体,且在不同环境下是特有的
2.大语言模型现在也很难将语言和三维场景联系起来,尤其是语言中包含视图引用或需要数字推理锁定目标时
3.需要大量语言和三维场景对齐的数据对模型进行训练,但目前缺少此类数据
作者是如何论述的?
●
引用了哪些该领域的开创性文献?●物体指代数据集
ReferIt3D,ScanRefer,SceneVerse,VLA-3D
VLA-3D有提及物体颜色,和尺寸等描述
ReferIt3D中的Nr3D有人类描述的语言
● 三维空间中大型语言模型的语义具象化1.3D-LLM:采用二维视觉语言模型作为主干网络,为了提取三维特征,该方式将输入的3D数据投影为多视角二维图像,利用ConceptFusion获取稠密二维特征,再通过这些二维嵌入重建三维表征。在此基础上实现改进(Grounded 3d-llm with referent tokens),能处理多视角语义具象化,并通过大规模语言-场景预训练泛化到各类三维任务。
2.LEO:利用预训练LLM,采用LoRA参数微调技术使其适配三维核心任务
● 加上了LLM的语义导航
NavGPT,NavCoT使用了vlm在2d视角下生成当前视角的语言描述,之后让llm根据下一个任务的语言指导选取下一步动作
🧩数据
本文的数据来源有哪些?
● ReferIt3D和VLA-3D
🔬方法
本文针对哪些问题应用了什么新方法?
● 1.使用了开放词汇物体过滤模块,对于复杂的空间指代问题首先使用LLM进行推理,但由于LLM在数学推理和空间理解方面的局限性,引入了模块化空间推理工具箱(预定义了基础空间关系计算规则),从而只需要单次工具箱使用示例,无需其他训练数据。2.如何精确理解三维物体的属性:
基于三维分割的方法可提供有效的物体中心化信息,但无法捕捉颜色、形状等细粒度属性,同时该方法需要大量数据集进行训练,目前仍缺少该方面的数据集
基于二维的方法(VLM)目前具有大量数据集,同时具备强大的物体理解先验知识。视觉问答(VQA)模型在场景物体描述方面表现卓越,故选用二维VQA模型作为场景中的三维物体生成描述文本,从而提供纯粹三维感知难以捕获的丰富视觉细节。
除此之外,当同一物体有多视角图像时,选用与目标标签CLIP相似度(CLIP计算图片与文本相似度(多幅图片与一个文本)_clip余弦相似度-CSDN博客)最高的视角,并选用Qwen2-7B为VLM基础模型,提示词如下:
“你是一个描述图像中查询物体特征的AI模型。请使用颜色、材质、形状、可供性及其他有意义的属性描述该图像中的<物体>。按此格式回复:’该<物体名称>呈<颜色>,材质为<材质>,形态呈<形状>’”
3.相关物体过滤器:
室内环境可能包含数百个物体,其中只有少数与特定语言查询或任务相关。为提取出来相关的物体进行了过滤,包含三个核心步骤:
1.从输入查询中提取被指代物体及其属性描述
2.基于所述属性从场景中选择相关物体子集
3.仅将该物体子集及其属性提供给下游推理代理
使用了Mistral Large模型执行上述步骤
4.空间推理工具箱:
将相关物体提取出来后输出给LLM,格式为{id,name,caption,c_x,c_y,c_z,size},其中id是物体的唯一性标识,c_x,c_y,c_z为物体中心的离散坐标。LLM提取到对应的物体后获得目标点输出给导航,但LLM缺少数学和空间推理能力,故引入空间推理工具箱。
该工具箱由启发式搜索函数组成,用于查找空间关系所指的对象,并根据满足关系的可能性对其进行排序。
📜结论
提出了什么不足与展望?
●1.需要联网调用api,但模块化设计可以让llm方便替换成本地小模型2.评估使用的数据集有限,没有全面评估该系统在各种场景下的能力
🤔思考
本文优缺点是什么?
●
你是否对某些内容产生了疑问?
●
哪些研究方式可以改进,如何改进?
●