很强劲啊 又开新坑
生成式AI
生成模型可以被理解为:从一个简单分布出发,通过某种动力系统,把样本变换到真实数据分布中。
换句话说,生成模型的核心问题是:
pinit⟶pdata
其中:
- pinit 是一个简单的初始分布,通常是高斯分布;
- pdata 是真实数据分布;
- 生成模型的任务是把从 pinit 中采样得到的噪声,逐渐变成像真实数据一样的样本。
从数据中生成样本的定义如下:

1. 从“生成”到“采样”
生成式 AI 的目标是生成新的对象,例如图像、视频、蛋白质结构、三维形状等。
在数学上,我们首先把这些对象表示成向量:
z∈Rd
例如:
- 一张图像可以看成一个由像素组成的高维向量;
- 一个视频可以看成多个图像帧组成的高维向量;
- 一个分子结构可以看成原子坐标组成的向量。
因此,所谓“生成一个对象”,在数学上可以理解为:
在高维空间中找到一个合理的点 z。
但什么叫“合理”?
如果我们想生成一张狗的图片,那么有些图片明显不像狗,有些图片虽然像动物但不是狗,有些图片则非常自然、合理。
为了把这个直觉形式化,我们引入数据分布。
2. 数据分布
真实世界中的数据并不是均匀分布在整个高维空间里的。
例如,随机生成一个像素矩阵,大概率只会得到噪声,而不是一张自然图像。
我们用数据分布表示真实数据在空间中的分布情况:
pdata(z)
它表示:
在真实数据中,样本 z 出现的可能性有多大。
如果一个样本看起来很自然、很符合真实数据,那么它在 pdata 下的概率密度就比较高。
如果一个样本只是随机噪声,那么它在 pdata 下的概率密度就很低。
因此,生成模型的目标可以写成:
z∼pdata
也就是说:
生成一个对象,本质上就是从真实数据分布中采样。
不过需要注意的是,在实际问题中,我们并不知道完整的 pdata。
我们拥有的只是一个有限的数据集:
{z1,z2,…,zN}
这个数据集可以看作是从真实数据分布中采样得到的一批样本。
3. 条件生成
很多生成任务不是随便生成一个样本,而是根据某个条件生成样本。
例如:
- 给定提示词 “dog”,生成狗的图片;
- 给定提示词 “cat”,生成猫的图片;
- 给定提示词 “landscape”,生成风景图。
我们把条件记为y
此时,模型不再是从整体数据分布 pdata(z) 中采样,而是从条件数据分布中采样:
pdata(z∣y)
它表示:
在给定条件 y 的情况下,样本 z 的分布是什么。
条件生成的目标就是:
z∼pdata(z∣y)
例如,当 y=“dog” 时,我们希望采样得到的是狗的图片;
当 y=“cat” 时,我们希望采样得到的是猫的图片。
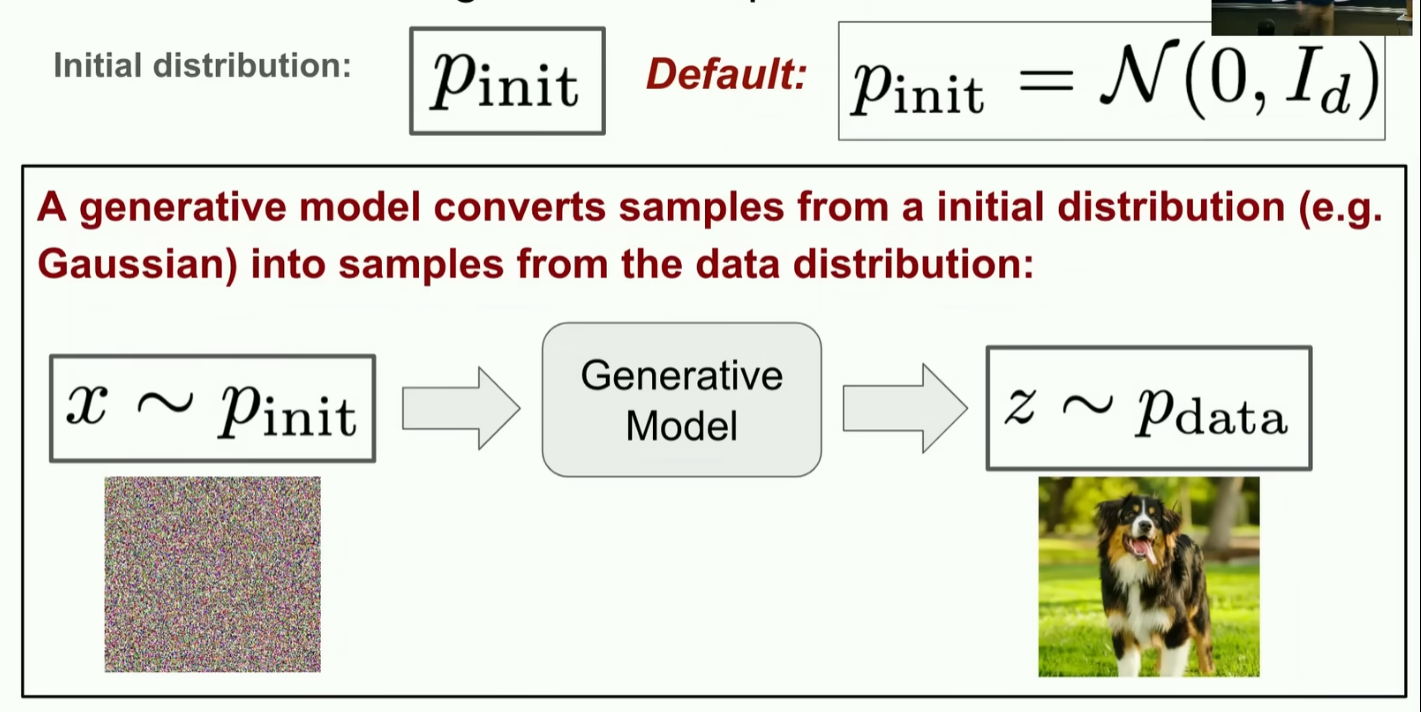
4. 生成模型的基本形式
虽然我们的目标是从 pdata 中采样,但真实的数据分布通常非常复杂,我们无法直接采样。
因此,生成模型通常采用一个间接的方法:
- 先从一个简单分布中采样;
- 再通过模型把这个简单样本变换成真实数据样本。
这个简单分布记作:
pinit
通常取为标准高斯分布:
pinit=N(0,I)
也就是说,我们先采样一个噪声:
x0∼pinit
然后通过生成模型得到:
x1∼pdata
因此,生成模型可以理解为一个分布变换过程:
pinit⟶pdata
5. Flow Models
5.1 Flow Model 的核心思想
Flow Model 的基本思想是:
用一个连续时间的运动过程,把初始噪声逐渐移动到数据分布中。
我们用 Xt 表示时间 t 时刻的样本状态,其中:
t∈[0,1]
当 t=0 时:
X0∼pinit
当 t=1 时:
X1∼pdata
所以整个生成过程可以写成:
X0→Xt→X1
直观理解就是:
一个点从噪声分布出发,沿着某条路径运动,最后到达数据分布。
5.2 轨迹
轨迹描述的是一个样本随时间变化的路径。
如果给定初始点 X0=x0,那么随着时间变化,这个点会形成一条曲线:
X={Xt}t∈[0,1]
也可以理解为一个函数:
t↦Xt
其中:
- X0 是初始状态;
- Xt 是中间状态;
- X1 是最终状态。
所以,轨迹回答的问题是:
一个具体样本从起点到终点是怎么走的?
5.3 向量场
为了描述样本如何运动,我们需要知道每个位置、每个时刻的运动方向和速度。
这就需要引入向量场。
向量场通常写作:
ut(x)
它表示:
在时间 t,如果样本位于位置 x,那么它应该以什么速度、朝什么方向运动。
也就是说,向量场是一个函数:
(x,t)↦ut(x)
输入:
输出:
- 一个和 x 维度相同的向量;
- 表示当前位置的速度方向和大小。
这里需要注意:
向量场不是一条轨迹,而是定义在整个空间上的运动规则。
轨迹是某一个点按照这个规则走出来的路径;
向量场则规定了所有点在所有时刻应该怎么运动。
5.4 ODE 表示
Flow Model 中的运动过程可以用常微分方程 ODE 表示:
dtdXt=ut(Xt)
其中:
- Xt 是当前样本的位置;
- ut(Xt) 是当前位置和当前时间下的速度;
- dtdXt 表示样本随时间变化的速度。
如果给定初始条件:(即沿着向量场的指定方向前进)
X0=x0
那么求解这个 ODE,就可以得到整条轨迹:
X0,Xt,X1
在生成模型中,我们关心的是最终结果 X1。
5.5 Flow Map
对于每一个初始点 x0,ODE 都会给出一个对应的运动结果,Flow map 可以看作由向量场产生的一族映射:
ψ:Rd×[0,1]→Rd
(x0,t)↦ψt(x0)
其中,x0 是初始点,t 是时间,ψt(x0) 表示从初始点 x0 出发,沿着向量场运动到时间 t 时的位置。它表示:
如果一个点从 x0 出发,沿着向量场运动到时间 t,它会到达哪里。
当 t=0 时,点还没有移动,所以:
ψ0(x0)=x0
Flow map 由向量场 ut 决定,它满足下面的微分方程:
dtdψt(x0)=ut(ψt(x0))
这个式子的含义是:
从 x0 出发的点在时间 t 的运动速度,等于向量场 ut 在当前位置 ψt(x0) 处给出的速度。
流可以被看做是针对许多初始条件的常微分方程解的集合,总体关系为向量场定义了常微分方程,而轨迹是这个常微分方程的一个解,流是不同初始条件下的轨迹集合

5.5.5 ODE的存在唯一性
为了让 Flow Model 是良好定义的,我们需要保证:
从任意初始点 x0 出发,ODE 都存在唯一解。
Picard–Lindelöf 定理说明,如果向量场 ut(x) 足够光滑,例如连续可微且导数有界,那么这个 ODE 存在唯一解。
更一般地,如果向量场满足 Lipschitz 条件:
∥ut(x)−ut(y)∥≤L∥x−y∥
那么 ODE 也有唯一解。
这意味着,从同一个初始点 x0 出发,轨迹是唯一确定的。因此 flow map
ψt(x0)
是良好定义的。
也就是说:
ψt(x0)=Xt
表示从初始点 x0 出发,沿着向量场运动到时间 t 时的位置。
只要向量场足够规整,从每个初始点出发的 ODE 轨迹就存在且唯一,因此 Flow Model 中的 flow map 是可以被正确定义的。
5.6 数值求解:Euler Method
在实际计算机中,我们无法真正连续地求解 ODE,因此需要离散化。
最简单的方法是 Euler Method。
设步长为:
h=n1
如果当前时刻是 t,当前位置是 Xt,那么下一步可以近似为:
Xt+h=Xt+hut(Xt)
直观理解:
在当前位置,看一下向量场指向哪里,然后沿这个方向前进一小步。
重复很多次之后,就可以从 X0 走到 X1。
这种方法很直观,但它有一个近似假设:在时间间隔 [t,t+h] 内,速度场的方向变化不大。因此 Euler method 只使用了“起点处的速度”。
Heun’s method 可以看作 Euler method 的改进版。它不是直接相信 Euler 给出的下一步,而是先用 Euler 方法预测一个位置,再根据预测位置处的速度对更新方向进行修正。
第一步,先用 Euler 方法预测下一步的位置:
Xt+h′=Xt+hut(Xt)
这里的 Xt+h′ 只是一个临时预测值,不是最终结果。
第二步,在预测位置 Xt+h′ 处重新计算速度场:
ut+h(Xt+h′)
然后将起点处的速度和预测终点处的速度取平均,得到最终更新:
Xt+h=Xt+2h(ut(Xt)+ut+h(Xt+h′))
从几何直觉上看,如果速度场在一步之内变化明显,Euler method 可能会沿着一开始的方向走偏;Heun’s method 则会参考预测终点处的方向,因此通常更准确。
5.7 Flow Model 如何生成样本
Flow Model 的目标是构造一个生成模型,使得它可以从简单分布出发,最终生成服从数据分布的样本。
具体来说,我们希望从一个容易采样的初始分布 pinit 出发,通过 ODE 演化,把噪声逐渐变成数据。
通常会选择标准高斯分布作为初始分布:
pinit=N(0,Id)
采样过程如下。
首先,从初始分布中采样一个随机初始点:
X0∼pinit
这里的随机性来自初始条件 X0。需要注意的是,ODE 本身是确定性的:一旦 X0 和 vector field 确定,整条轨迹也就确定了。因此 Flow Model 通过随机初始化 X0 来生成不同样本。
然后,使用一个由神经网络参数化的 vector field:
utθ:Rd×[0,1]→Rd
它接收当前位置 Xt 和时间 t,输出当前位置处的速度方向:
utθ(Xt)
Flow Model 对应的 ODE 为:
dtdXt=utθ(Xt)
也就是说,样本点会沿着神经网络给出的速度场从 t=0 演化到 t=1。
如果用 flow map 表示这条由 ODE 诱导出的变换,可以写成:
X1=ψ1θ(X0)
我们的目标是让最终得到的样本 X1 服从数据分布:
X1∼pdata
等价地说,希望:
ψ1θ(X0)∼pdata
其中:
X0∼pinit
需要注意的是,虽然它叫 Flow Model,但神经网络本身并不是直接参数化 flow map ψtθ,而是参数化 vector field utθ。真正的 flow ψtθ 是通过模拟 ODE 得到的。
实际采样时,通常不能直接解析求解这个 ODE,所以需要用数值方法近似模拟。最简单的方法是 Euler method。
给定步数 n,令步长为:
h=n1
初始化:
t=0,X0∼pinit
然后重复更新:
Xt+h=Xt+hutθ(Xt)
并令:
t←t+h
直到 t=1。
最后返回:
X1
作为生成出的样本。
因此,Flow Model 的生成过程可以概括为:
- 从简单分布 pinit 中采样噪声 X0;
- 用神经网络 vector field utθ 定义 ODE;
- 从 t=0 到 t=1 数值模拟这条 ODE;
- 返回最终点 X1;
- 训练目标是让 X1 的分布尽可能接近数据分布 pdata。
简而言之:
X0∼pinitODE driven by utθX1∼pdata
Flow Model 就是在学习一个速度场,让简单噪声分布中的点沿着这个速度场运动后,最终变成数据分布中的样本。
6. Diffusion Models
6.1 从 ODE 到 SDE
Flow Model 使用的是确定性的 ODE:
dXt=ut(Xt)dt
或者写成更常见的导数形式:
dtdXt=ut(Xt)
如果初始点 X0 确定,并且 vector field ut 确定,那么整条轨迹也是确定的。
也就是说,同一个初始点每次都会沿着同一条路径运动。
Diffusion Model 则在这个过程中加入随机性,也就是把 ODE 扩展为 SDE(Stochastic Differential Equation,随机微分方程):
dXt=ut(Xt)dt+σtdWt
其中:
- ut(Xt)dt 是确定性的运动部分,也叫 drift term;
- ut 可以理解为 drift coefficient,控制样本主要往哪个方向运动;
- dWt 是 Brownian Motion 的无穷小增量,用来引入随机噪声;
- σt 是 diffusion coefficient,也就是扩散系数;
- σt 控制随机噪声的强度。
可以概括为:
drift coefficient ut 控制方向,diffusion coefficient σt 控制随机性

当:
σt=0
时,随机项消失,SDE 就退化成 ODE:
dXt=ut(Xt)dt
因此可以理解为:
Flow Model 是没有随机噪声的情形,Diffusion Model 是带随机噪声的情形。
也就是说,ODE 可以看作 SDE 的特殊情况。
为了更直观地理解 SDE,可以先把 ODE 改写成小步更新的形式。
ODE 的导数形式是:
dtdXt=ut(Xt)
根据导数定义,当步长 h 很小时,可以近似写成:
h1(Xt+h−Xt)=ut(Xt)+Rt(h)
也就是:
Xt+h=Xt+hut(Xt)+hRt(h)
其中 Rt(h) 是误差项,并且当 h→0 时:
Rt(h)→0
这说明 ODE 的轨迹在每个小时间步里,都会沿着当前 vector field 的方向走一小步:
Xt⟶Xt+hut(Xt)
SDE 的做法就是在这个小步更新的基础上,再加入一个来自 Brownian Motion 的随机扰动:
Xt+h=Xt+hut(Xt)+σt(Wt+h−Wt)+hRt(h)
其中:
hut(Xt)
是确定性部分;
σt(Wt+h−Wt)
是随机部分;
hRt(h)
是误差项。
所以 SDE 可以理解为:
每一步既按照 vector field 指定的方向前进,又额外加入一小段随机扰动。
这也是为什么 SDE 的轨迹不再是完全确定的。
在 ODE 中,如果给定 X0,那么 Xt 由 X0 唯一决定,因此可以定义一个确定性的 flow map:
Xt=ψt(X0)
但在 SDE 中,即使 X0 相同,每次采样到的 Brownian Motion 路径也可能不同,所以最终轨迹也可能不同。因此 SDE 一般没有像 ODE 那样的确定性 flow map。
6.2 Brownian Motion
SDE 中的随机性通常来自 Brownian Motion,也叫 Wiener Process。
Brownian Motion 记作:
Wt
它可以理解为连续时间中的随机游走。
Brownian Motion 满足:
W0=0
也就是说,它在时间 t=0 时从 0 出发。
Brownian Motion 有两个重要性质。
第一,增量服从高斯分布。
对于 0≤s<t,有:
Wt−Ws∼N(0,(t−s)Id)
如果令 s=t,下一个时间点是 t+h,则有:
Wt+h−Wt∼N(0,hId)
也就是说,时间间隔越大,随机变化的方差越大。
它的方差会随着时间间隔线性增长。
第二,不同时间段的增量相互独立。
如果有一组时间点:
0≤t0<t1<⋯<tn
那么这些增量:
Wt1−Wt0,Wt2−Wt1,…,Wtn−Wtn−1
彼此独立。
也就是说,Brownian Motion 在不重叠时间段中的随机变化互不影响。
直观来说,Brownian Motion 描述的是一种连续时间中的随机游走。
它有两个看起来有点矛盾但很重要的特点:
- 路径是连续的;
- 但路径非常不光滑,不能像普通函数那样直接求导。

这也是为什么从 ODE 进入 SDE 时,不能继续直接使用:
dtdXt
来严格描述随机轨迹,而是要用:
dXt=ut(Xt)dt+σtdWt
这样的随机微分方程记号。
Brownian Motion 可以用离散小步近似模拟。
设步长为 h,从:
W0=0
开始,每一步更新为:
Wt+h=Wt+hϵt
其中:
ϵt∼N(0,Id)
这是因为:
Wt+h−Wt∼N(0,hId)
而如果:
ϵt∼N(0,Id)
那么:
hϵt∼N(0,hId)
所以可以用:
hϵt
来模拟 Brownian Motion 在一个小时间步中的随机增量。
6.3 如何数值模拟 SDE:Euler-Maruyama Method
ODE 可以用 Euler Method 近似模拟:
Xt+h=Xt+hut(Xt)
SDE 也有类似的数值方法,叫 Euler-Maruyama Method。
对于 SDE:
dXt=ut(Xt)dt+σtdWt
它的离散更新公式是:
Xt+h=Xt+hut(Xt)+σthϵt
其中:
ϵt∼N(0,Id)
这个式子可以分成两部分理解:
hut(Xt)
是确定性的 drift step,也就是沿着 vector field 前进一小步;
σthϵt
是随机的 diffusion step,也就是加入一小段高斯噪声。
所以 Euler-Maruyama Method 可以理解为:
每一步先按照 vector field 走一小步,再加入一小段由 Brownian Motion 产生的随机噪声。
如果用神经网络参数化 vector field,则 Diffusion Model 可以写成:
X0∼pinit
dXt=utθ(Xt)dt+σtdWt
实际采样时,给定步数 n,令:
h=n1
然后从初始分布采样:
X0∼pinit
并不断更新:
Xt+h=Xt+hutθ(Xt)+σthϵt
直到 t=1。
最终返回:
X1
作为生成样本。
目标是让:
X1∼pdata
因此,Diffusion Model 的采样过程可以概括为:
X0∼pinitSDE driven by utθ and σtdWtX1∼pdata
6.4 Diffusion Model 如何生成样本
Diffusion Model 的生成过程可以理解为:
- 从初始分布中采样:
X0∼pinit
- 按照 SDE 演化:
dXt=ut(Xt)dt+σtdWt
-
使用 Euler-Maruyama Method 逐步模拟;
-
最终得到:
X1∼pdata
在机器学习中,通常会用神经网络来参数化其中的向量场:
uθ(x,t)
也就是说,模型要学习的是:
在每个时间、每个位置,样本应该如何运动。
扩散系数 σt 通常是预先设定的,而神经网络主要负责学习运动方向。
7. Flow Model 与 Diffusion Model 的对比
| 模型 | 数学形式 | 是否随机 | 数值方法 | 核心思想 |
|---|
| Flow Model | ODE | 否 | Euler Method / ODE Solver | 沿确定性向量场从噪声走到数据 |
| Diffusion Model | SDE | 是 | Euler-Maruyama Method | 在确定性运动基础上加入随机扩散 |
| 关系 | 当 σt=0 时,SDE 退化为 ODE | - | - | Flow Model 可看作 Diffusion Model 的特殊情况 |
8. 本讲的核心理解
第一讲最重要的主线是:
生成模型不是凭空“画”出一个样本,而是把一个简单分布中的样本,通过某种动力系统,变换成数据分布中的样本。
这个动力系统可以有两种形式。
第一种是 ODE,对应 Flow Model:
dtdXt=ut(Xt)
第二种是 SDE,对应 Diffusion Model:
dXt=ut(Xt)dt+σtdWt
二者的共同目标都是:
pinit⟶pdata
也就是从简单分布生成复杂数据分布。
9. 容易混淆的地方
9.1 轨迹和向量场不是一个东西
轨迹是一个具体样本走出来的路径:
t↦Xt
向量场是整个空间中的运动规则:
(x,t)↦ut(x)
一个向量场可以产生无数条轨迹。
每一个不同的初始点,都可以沿着同一个向量场生成一条不同的轨迹。
9.2 pdata 通常是未知的
我们想从 pdata 中采样,但实际上并不知道这个分布的完整形式。
我们只有数据集:
{z1,z2,…,zN}
模型训练的目的就是利用这些有限样本,学习一个能够近似生成真实数据分布的过程。
生成式AI的训练目标
在上一节中,我们构造了 flow models 和 diffusion models。它们都是由神经网络向量场 utθ 参数化的生成模型。
不过,我们还没有讨论如何训练它们。也就是说,我们还没有讨论如何优化参数 θ,使得生成模型能够输出有意义的结果,比如一张好看的图像,或者一段有趣的视频。
接下来,我们将讨论 Flow Matching。Flow Matching 是一种用于训练 utθ 的算法,它简单、可扩展,并且代表了当前的 state-of-the-art 方法。
在本节中,我们先只关注 flow models。也就是说,我们有一个神经网络 utθ,并通过模拟下面这个 ODE 来从生成模型中采样:
X0∼pinit,dXt=utθ(Xt)dt
也就是:
Flow model
然后,我们把 t=1 时的终点 X1 作为生成样本。
正如前面讨论过的,我们的目标是让 X1 服从数据分布 pdata,也就是:
X1∼pdata
因此,“如何训练”这个神经网络,本质上就是在问:
我们应该如何优化参数 θ,使得模拟式中的 flow model 之后,得到的样本 X1 服从数据分布 pdata?
换句话说,我们希望通过训练 utθ,让从简单初始分布 pinit 出发的 ODE 轨迹,最终在 t=1 时到达数据分布。
区分Conditional 和 Marginal
- conditional表示围绕某一个具体数据点z的情况
- marginal表示对整个数据分布平均之后的整体情况
1. Probability Path:从噪声分布到数据分布的路径
生成模型的目标是把一个简单、容易采样的初始分布变成真实数据分布:
pinit⟶pdata
在 Flow Model 中,我们希望 ODE 轨迹满足:
X0∼pinit
并且在最终时刻:
X1∼pdata
也就是说,t=0 时样本来自噪声分布,t=1 时样本来自数据分布。
但只知道起点和终点还不够。我们还需要描述中间时刻:
0<t<1
样本整体应该服从什么分布。
因此,引入一条随时间变化的概率分布路径:
(pt)0≤t≤1
并希望它满足:
p0=pinit
p1=pdata
这条路径就叫做 probability path。
直观来说,probability path 描述的是:
在每个时间 t,样本整体应该服从什么分布。
或者说,pt 是从噪声分布到数据分布的一条连续变化路径。
下图是原文 Figure 4。它展示了通过 Gaussian conditional probability path,将噪声逐渐插值到图像数据的过程。
这里每一张图像本身都是一个数据点,维度为:
d=32×32
所以这张图展示的是 probability path 中的单个样本如何随时间变化。

而下图是原文 Figure 5。它展示的不是单张图像样本,而是二维空间中的概率分布本身,并用二维直方图可视化。

图 5 中使用的是一个二维 toy example,而不是图像数据。这里的数据分布 pdata 是一个棋盘格形状的分布,方便我们直接看到“分布如何从噪声变成数据”。
图 5 分成上下两排:
- 上排是 conditional probability path;
- 下排是 marginal probability path。
并且每一列对应一个不同的时间 t。
从左到右,时间逐渐增加:
t=0⟶t=1
2. Conditional Probability Path
2.1 定义
给定一个真实数据点:
z∈Rd
我们可以构造一条围绕这个数据点 z 的条件概率路径:
pt(⋅∣z)
它表示:
在给定目标数据点 z 的情况下,时间 t 时中间样本的分布。
这里的 ⋅ 是占位符,表示这个分布作用在所有可能的 x 上。
也可以写成:
pt(x∣z)
表示在时间 t,给定目标数据点 z 时,样本位于 x 附近的概率密度。
conditional probability path 需要满足:
p0(⋅∣z)=pinit
p1(⋅∣z)=δz
其中,δz 表示位于 z 的 Dirac delta distribution。
它可以理解为一种最简单的分布:从 δz 中采样时,永远都会得到 z。
也就是说:
X∼δz⟹X=z
因此,conditional probability path 的含义是:
给定某一个数据点 z,构造一条从噪声分布 pinit 逐渐走向单个数据点 z 的分布路径。
也可以理解为:
pinit⟶δz
注意,这里的终点不是整个数据分布 pdata,而是某一个固定数据点 z。
2.2 Gaussian Conditional Probability Path
最常用的一类 conditional probability path 是 Gaussian conditional probability path。
它定义为:
pt(⋅∣z)=N(αtz,βt2Id)
也可以写成密度形式:
pt(x∣z)=N(x;αtz,βt2Id)
这表示:在时间 t,给定目标数据点 z,中间样本服从一个高斯分布。
其中:
- 均值是 αtz;
- 方差是 βt2Id;
- Id 是 d 维单位矩阵;
- αt 控制数据点 z 的比例;
- βt 控制噪声强度。
等价地,可以写成采样形式:
Xt=αtz+βtϵ,ϵ∼N(0,Id)
为了让它从噪声走到数据点,需要满足:
α0=0,β0=1
此时:
X0=ϵ∼N(0,Id)
也就是初始噪声分布。
同时还需要满足:
α1=1,β1=0
此时:
X1=z
也就是最终到达数据点本身。
所以 Gaussian conditional probability path 可以理解为:
用一个逐渐移动、逐渐收缩的高斯分布,把噪声分布变成某一个具体数据点。
更直观地说:
- 当 t 接近 0 时,αt 小、βt 大,样本主要是噪声;
- 当 t 接近 1 时,αt 大、βt 小,样本越来越接近数据点 z;
- 当 t=1 时,噪声完全消失,样本变成 z。
2.3 如何理解图 5 上排:Conditional Probability Path
图 5 上排画的是 conditional probability path:
pt(x∣z)
也就是在固定某一个数据点 z 的情况下,时间 t 时 x 的分布。
图中使用的是 Gaussian conditional probability path,并且取:
αt=t,βt=1−t
所以:
pt(x∣z)=N(tz,(1−t)2Id)
也可以写成采样形式:
Xt=tz+(1−t)ϵ,ϵ∼N(0,Id)
这时从左到右可以这样理解:
当 t=0 时:
X0=ϵ
因此:
p0(x∣z)=N(0,Id)
这时分布和 z 没有关系,所以图中看到的是一个位于原点附近的高斯噪声团。
当 t 增大时:
Xt=tz+(1−t)ϵ
里面的数据成分 tz 变多,噪声成分 (1−t)ϵ 变少。
因此,上排的高斯分布会发生两件事:
- 它的中心逐渐从原点移动到目标数据点 z;
- 它的方差逐渐变小,也就是分布越来越集中。
当 t=1 时:
X1=z
所以:
p1(x∣z)=δz
这时分布收缩成单个点 z。
因此,图 5 上排想表达的是:
如果目标数据点 z 已经固定,那么 conditional path 会把一个标准高斯噪声分布,逐渐移动并收缩到这个具体的数据点 z 上。
所以它描述的是:
N(0,Id)⟶δz
这就是 conditional probability path 的含义。
3. Marginal Probability Path
前面构造的是 conditional probability path:
pt(x∣z)
它表示:给定某一个数据点 z 时,时间 t 的中间样本分布。
但是生成模型最终不是只针对某一个固定的数据点 z,而是要生成整个数据分布:
pdata
所以我们需要把所有数据点对应的 conditional path 混合起来,得到 marginal probability path:
pt(x)=∫pt(x∣z)pdata(z)dz
也就是说,对所有可能的数据点 z,把它们对应的路径 pt(x∣z) 按照 pdata(z) 加权平均。
这个构造过程可以理解为:
- 先从真实数据分布中采样一个数据点:
z∼pdata
- 在给定这个数据点 z 的条件下,从 conditional path 中采样:
Xt∣z∼pt(⋅∣z)
- 如果不再关心具体采到了哪个 z,只看 Xt 本身的分布,那么:
Xt∼pt
因此:
z∼pdata,Xt∣z∼pt(⋅∣z)⟹Xt∼pt
这个 pt 就是 marginal probability path。
3.1 如何理解图 5 下排:Marginal Probability Path
图 5 下排画的是 marginal probability path:
pt(x)
它不是固定某一个数据点 z,而是考虑所有可能的数据点:
z∼pdata
在这个二维 toy example 里,pdata 是一个棋盘格形状的分布。
marginal path 的采样方式是:
z∼pdata,ϵ∼N(0,Id)
然后令:
Xt=tz+(1−t)ϵ
这时,如果不关心具体采到了哪个 z,只看所有 Xt 的整体分布,就得到:
Xt∼pt
因此,图 5 下排可以理解为:
对数据分布里的每一个可能数据点 z,都构造一条从噪声到 z 的 conditional path;然后把这些路径全部混合起来,得到整体的 marginal path。
从左到右看:
当 t=0 时:
X0=ϵ
所以所有样本都来自标准高斯分布:
p0=N(0,Id)
此时虽然我们也采样了:
z∼pdata
但因为:
X0=0⋅z+1⋅ϵ
数据点 z 完全不起作用,所以整体分布仍然只是一个高斯噪声团。
当 t 稍微变大时,例如 t=0.25:
Xt=0.25z+0.75ϵ
这时样本仍然有很强的噪声成分,所以整体看起来仍然比较模糊。
但因为 z 已经开始参与进来,分布会开始受到数据分布形状的影响。
当 t=0.5 时:
Xt=0.5z+0.5ϵ
数据成分和噪声成分差不多。
此时可以开始看到棋盘格结构的雏形,但由于噪声仍然较大,不同区域之间还会有明显的模糊和重叠。
当 t=0.75 时:
Xt=0.75z+0.25ϵ
数据成分已经占主导,噪声成分变小。
所以图中棋盘格结构会变得更加清楚,不同高密度区域之间的边界更加明显。
当 t=1 时:
X1=z
而:
z∼pdata
所以:
p1=pdata
这时 marginal path 的终点就是完整的数据分布,也就是图中的棋盘格分布。
因此,图 5 下排想表达的是:
N(0,Id)⟶pdata
也就是从一个简单高斯分布,逐渐变成整个数据分布。
3.2 conditional path & marginal path
对于每一个固定的数据点 z,都有一条 conditional path:
pt(x∣z)
如果数据分布中有很多可能的数据点,那么每个数据点都会对应一条这样的路径。
marginal path 本质上就是把这些路径按照数据分布的权重混合起来:
pt(x)=∫pt(x∣z)pdata(z)dz
这里的:
pdata(z)
表示数据点 z 在真实数据分布中的权重。
如果某类数据点出现得更多,那么它对应的 conditional paths 在 marginal path 中的权重也更大。
所以 marginal path 并不是凭空定义出来的,而是由 conditional path 自动诱导出来的。
也就是说:
conditional path pt(x∣z)+z∼pdata⟹marginal path pt(x)
这也是 Flow Matching 后面能够训练的关键:
我们真正想学的是能生成整个数据分布的 marginal path;
但训练时更容易构造和采样的是 conditional path.
虽然 marginal probability path 的密度可以写成:
pt(x)=∫pt(x∣z)pdata(z)dz
但这个积分通常是不可计算的。
也就是说,我们一般无法直接算出某个点 x 在 marginal path 下的密度值 pt(x)。
但是,我们可以很容易地从 pt 中采样。
对于 Gaussian path,只需要:
z∼pdata,ϵ∼N(0,Id)
然后令:
Xt=αtz+βtϵ
于是:
Xt∼pt
所以这里有一个重要区别:
我们能从 pt 采样,但通常不能显式计算 pt(x)
这一点后面很重要,因为 Flow Matching 的训练会利用容易采样的 conditional path,而避免直接计算复杂的 marginal density。
4.Conditional Vector Field
4.1 Conditional Vector Field 的定义
前面我们已经构造了 conditional probability path:
pt(x∣z)
它表示:在给定某个数据点 z 的情况下,时间 t 时中间样本 x 的分布。
现在我们希望找到一个向量场:
uttarget(x∣z)
这个向量场叫作 conditional vector field。
它是一个依赖于数据点 z 的速度场,可以理解为一个函数:
(x,t,z)↦uttarget(x∣z)
其中:
- x 是当前样本的位置;
- t 是当前时间;
- z 是给定的目标数据点;
- uttarget(x∣z) 是当前位置 x 在时间 t 下应该具有的速度。
所以 conditional vector field 的含义是:
给定目标数据点 z,如果当前样本位于 x,时间为 t,那么它应该以什么速度运动。
它和普通 vector field 的区别在于,普通 vector field 写作:
ut(x)
只依赖当前位置 x 和时间 t。
而 conditional vector field 写作:
ut(x∣z)
它还依赖于目标数据点 z。
也就是说,不同的 z 会对应不同的速度场。
4.2 Conditional Vector Field 应该满足什么性质?
conditional vector field 需要满足下面这个性质:
如果初始样本来自 conditional path 的起点:
X0∼p0(⋅∣z)
并且样本按照 ODE 运动:
dtdXt=uttarget(Xt∣z)
那么在任意时间 t,样本分布都应该满足:
Xt∼pt(⋅∣z)
也就是说,这个向量场需要让 ODE 的分布正好沿着 conditional probability path 走。
因此可以把 conditional vector field 定义为:
能够通过 ODE 把条件路径 pt(⋅∣z) 实现出来的速度场。
换句话说,conditional probability path 告诉我们:
每个时间 t 的分布应该是什么
而 conditional vector field 告诉我们:
样本应该怎么运动,才能产生这条分布路径
4.3 从分布角度看 Conditional Vector Field
更严格地说,如果一个向量场 uttarget(x∣z) 能够产生 conditional probability path pt(x∣z),那么它们应该满足 conditional continuity equation:
∂t∂pt(x∣z)=−div(pt(x∣z)uttarget(x∣z))
这个方程的意思是:
条件分布 pt(x∣z) 的变化,是由向量场 uttarget(x∣z) 搬运概率质量造成的。
所以 conditional vector field 的作用可以总结为:
uttarget(x∣z)⟹pt(x∣z) 按照这条路径演化
4.4 直观理解
可以把每个数据点 z 想象成一个目标点。
对于每个目标点 z,我们都构造一条 conditional probability path:
pt(⋅∣z)
这条路径描述了:
一团噪声如何逐渐移动并收缩到数据点 z 附近。
而 conditional vector field:
uttarget(x∣z)
描述的是:
在这条路径上,每个中间点 x 应该往哪里走。
所以:
- conditional probability path 描述“分布应该长什么样”;
- conditional vector field 描述“样本应该怎么动”。
一句话理解:
Conditional vector field 是实现 conditional probability path 的速度场。
4.5 Gaussian Path 下的 Conditional Vector Field
对于Gaussian path有
Xt=αtz+βtϵ
其中:ϵ∼N(0,Id)
对时间 t 求导:
dtdXt=α˙tz+β˙tϵ
但是向量场应该写成关于当前状态 x 和数据点 z 的函数,而不是关于 ϵ 的函数。
由x=αtz+βtϵ可得ϵ=βtx−αtz
代回去:dtdXt=α˙tz+β˙tβtx−αtz
展开:dtdXt=α˙tz+βtβ˙tx−βtβ˙tαtz
整理得到:uttarget(x∣z)=(α˙t−βtβ˙tαt)z+βtβ˙tx
该式子可以理解为:
当前点 x 的速度由两部分决定:一部分和目标数据点 z 有关,另一部分和当前位置 x 有关。
其中:(α˙t−βtβ˙tαt)z
表示把样本往数据点 z 的方向推。
而:βtβ˙tx
表示根据噪声尺度 βt 的变化,对当前位置做收缩或扩张。
如果 βt 逐渐变小,那么这个过程会把围绕数据点的高斯分布逐渐压缩,最后集中到 z 附近。
5. Marginal Vector Field
5.1 为什么需要 Marginal Vector Field?
前面我们定义了 conditional vector field:
uttarget(x∣z)
它表示:
给定某一个数据点 z 时,当前点 x 在时间 t 应该以什么速度运动。
但是在真正生成的时候,我们并没有一个固定的目标数据点 z。
生成时只有:
X0∼pinit
然后希望通过一个 ODE:
dtdXt=uttarget(Xt)
最终得到:
X1∼pdata
所以 Flow Model 真正需要的不是依赖某个数据点 z 的 conditional vector field,而是一个整体的速度场:
uttarget(x)
这个整体速度场就叫作 marginal vector field。
5.2 Marginal Vector Field 的定义
Marginal vector field 定义为:
uttarget(x)=∫uttarget(x∣z)pt(x)pt(x∣z)pdata(z)dz
即
uttarget(x)=∫uttarget(x∣z)pt(z∣x)dz
其中:
pt(x)=∫pt(x∣z)pdata(z)dz
pt(z∣x)
表示:
在时间 t,观察到当前中间点 x 时,它可能来自哪个数据点 z。
这个公式的含义是:
marginal vector field 是在当前点 x 处,对所有可能的目标数据点 z 的 conditional vector field 做后验加权平均
也就是说,在当前点 x 处,可能有很多个数据点 z 的 conditional path 会经过这里。
每个数据点 z 都会给出一个速度:
uttarget(x∣z)
marginal vector field 就是把这些可能速度按照权重平均起来。
5.3 直观理解
可以这样想:
每个数据点 z 都有一条自己的 conditional probability path:
pt(x∣z)
也有对应的 conditional vector field:
uttarget(x∣z)
如果当前中间点是 x,它可能来自很多不同的数据点:
z1,z2,z3,…
对于每个可能的 zi,都有一个“建议速度”:
uttarget(x∣zi)
但是生成模型不知道当前点 x 具体应该走向哪个训练样本,所以它需要综合这些建议。
因此:
uttarget(x)
就是所有可能 conditional velocity 的平均结果。
简单说:
conditional vector field:给定某个 z 时应该怎么走
marginal vector field:不知道具体 z 时,综合所有可能 z 后应该怎么走
5.4 Marginal Vector Field 的推导
已知每个 conditional path 满足 conditional continuity equation:
∂t∂pt(x∣z)=−div(pt(x∣z)uttarget(x∣z))
marginal path 定义为:
pt(x)=∫pt(x∣z)pdata(z)dz
对时间求导:
∂t∂pt(x)=∫∂t∂pt(x∣z)pdata(z)dz
代入 conditional continuity equation:
∂t∂pt(x)=−∫div(pt(x∣z)uttarget(x∣z))pdata(z)dz
把散度放到积分外:
∂t∂pt(x)=−div(∫pt(x∣z)uttarget(x∣z)pdata(z)dz)
我们希望 marginal path 也满足 continuity equation:
∂t∂pt(x)=−div(pt(x)uttarget(x))
所以需要:
pt(x)uttarget(x)=∫pt(x∣z)uttarget(x∣z)pdata(z)dz
两边除以 pt(x):
uttarget(x)=∫uttarget(x∣z)pt(x)pt(x∣z)pdata(z)dz
这就是 marginal vector field 的公式。
6. Continuity Equation
6.1 ODE 如何影响概率分布?
Flow Model 中,单个样本按照 ODE 运动:
dtdXt=ut(Xt)
但是训练生成模型时,我们关心的不是单个点,而是整个分布:
Xt∼pt
因此需要一个方程描述:
当所有点都按照向量场 ut 运动时,概率密度 pt(x) 如何变化?
这个方程就是 continuity equation。
6.2 Continuity Equation 的公式
如果:
X0∼pinit
并且:
dtdXt=ut(Xt)
那么 Xt 的分布 pt 满足:
dtdpt(x)=−div(ptut)(x)
其中:
- div 是散度;
- ptut 可以理解为 probability mass 的流量;
- 右边描述了概率质量从点 x 附近流入或流出的情况。
6.3 直观解释
Continuity equation 可以理解为概率质量守恒:
某处概率密度的变化=流入的概率质量−流出的概率质量
如果一个区域流入的概率质量比流出的多,那么这个区域的概率密度会上升。
如果流出的概率质量比流入的多,那么这个区域的概率密度会下降。
因此:
−div(ptut)(x)
就是在描述由于向量场搬运概率质量而造成的密度变化。
Continuity equation 是连接下面两个层面的桥梁:
单个样本层面:
dtdXt=ut(Xt)
整体分布层面:
Xt∼pt
它告诉我们:
如果想让 ODE 的样本分布沿着某条 probability path pt 走,那么向量场 ut 必须让 pt 满足 continuity equation。
这也是 marginal vector field 公式成立的数学基础。
7. Conditional Score Function
7.1 Conditional Score Function 的定义
前面我们定义了 conditional probability path:
pt(x∣z)
它表示:给定某一个数据点 z 时,时间 t 的中间样本 x 的概率分布。
在这个条件分布上,我们可以定义 conditional score function:
∇xlogpt(x∣z)
它表示:
在给定数据点 z 的情况下,时间 t 时,当前位置 x 的概率密度上升最快的方向。
7.2 score function 的直观理解
score function 是 log probability density 的梯度:
∇xlogpt(x∣z)
可以把概率密度想象成一张地形图:
- 概率密度高的地方像山峰;
- 概率密度低的地方像山谷;
- score function 指向“往山上走最快”的方向。
所以:
∇xlogpt(x∣z)
告诉我们:
在 conditional distribution pt(x∣z) 中,如果当前点是 x,应该往哪个方向移动,概率密度会增加得最快。
对于生成模型来说,这个方向很重要,因为它可以告诉样本如何从低概率区域移动到高概率区域。
7.3 Gaussian Path 下的 Conditional Score
对于 Gaussian conditional probability path:
pt(x∣z)=N(αtz,βt2Id)
它的均值是:
αtz
协方差是:
βt2Id
因此它的 log density(先取概率密度函数 p(x),再对它取对数,得到 logp(x)) 中和 x 有关的部分是:
−2βt21∥x−αtz∥2
对 x 求梯度:
∇xlogpt(x∣z)=−βt2x−αtz
这就是 Gaussian path 下的 conditional score function。
该公式中:
- αtz 是当前 conditional Gaussian 的中心;
- x−αtz 表示当前点 x 偏离中心的方向;
- 前面的负号表示把 x 往中心 αtz 拉回去;
- βt2 是方差,控制拉回去的强度。
如果 x 离中心很远,那么 score 的大小较大,说明应该更强地往中心移动。
如果 x 已经很接近中心,那么 score 接近 0,说明它已经在高概率区域附近。
所以 Gaussian conditional score 的作用是:
把当前点 x 往 conditional distribution 的中心 αtz 拉回去。
8. Marginal Score Function
∇xlogpt(x)=∫∇xlogpt(x∣z)pt(x)pt(x∣z)pdata(z)dz
含义:
对所有可能数据点 z 的 conditional score 做后验加权平均,得到整体分布 pt 的 score。
也可以写成:
∇xlogpt(x)=E[∇xlogpt(x∣z)∣x]
它是 Diffusion Model 真正需要学习的对象。
理解:
- conditional score:已知 z 时,哪里概率更高;
- marginal score:不知道具体 z 时,整体分布中哪里概率更高。
9. SDE 与 Fokker–Planck Equation
9.1 从 ODE 到 SDE
前面 Flow Model 使用的是 ODE:
dXt=ut(Xt)dt
这个式子表示:
样本 Xt 按照向量场 ut 确定性地运动。
也就是说,如果初始点 X0 已经确定,那么后面的整条轨迹也是确定的。
Diffusion Model 使用的是 SDE:
dXt=ut(Xt)dt+σtdWt
它比 ODE 多了一项随机噪声:
σtdWt
其中:
- ut(Xt)dt 是确定性的运动项,也叫 drift term;
- σtdWt 是随机扩散项,也叫 diffusion term;
- σt 是 diffusion coefficient,用来控制随机噪声的强度;
- Wt 是 Brownian motion,也叫 Wiener process。
所以可以这样理解:
ODE 描述确定性运动。
SDE 描述确定性运动加随机扰动。
如果:
σt=0
那么随机项消失,SDE 就退化成 ODE:
dXt=ut(Xt)dt
9.2 为什么需要 Fokker–Planck Equation?
ODE 和 SDE 描述的是单个样本怎么运动。
例如:
dXt=ut(Xt)dt+σtdWt
这个式子描述的是某一个样本 Xt 的运动过程。
但是生成模型真正关心的不是单个样本,而是整个样本分布。
也就是说,我们真正关心的是:
Xt∼pt
其中,pt 表示时间 t 时所有样本形成的概率分布。
因此我们需要一个方程来描述:
如果每个样本都按照 SDE 运动,那么整体概率密度 pt(x) 会如何变化?
这个描述 SDE 下概率密度演化的方程,就是 Fokker–Planck Equation。
9.3 先回顾 ODE 对应的 Continuity Equation
对于 ODE:
dXt=ut(Xt)dt
也可以写作:
dtdXt=ut(Xt)
如果:
Xt∼pt
那么分布 pt(x) 的变化满足 continuity equation:
∂t∂pt(x)=−div(ptut)(x)
这个式子的直观含义是:
概率密度的变化来自概率质量的流动。
其中:
pt(x)ut(x)
可以理解为概率质量的流量。
如果某个区域流入的概率质量多,流出的概率质量少,那么这个区域的概率密度会上升。
如果某个区域流出的概率质量多,流入的概率质量少,那么这个区域的概率密度会下降。
因此,continuity equation 描述的是:
在确定性向量场 ut 搬运下,概率分布 pt 如何变化。
9.4 SDE 对应的 Fokker–Planck Equation
对于 SDE:
dXt=ut(Xt)dt+σtdWt
如果:
Xt∼pt
那么概率密度 pt(x) 满足:
∂t∂pt(x)=−div(ptut)(x)+2σt2Δpt(x)
这就是 Fokker–Planck Equation。
它比 continuity equation 多了一项:
2σt2Δpt(x)
因为 SDE 比 ODE 多了随机噪声:
σtdWt
所以 Fokker–Planck Equation 可以理解为:
SDE 下的分布变化 = 确定性流动造成的变化 + 随机扩散造成的变化。
9.5 公式中每一项的含义
Fokker–Planck Equation 是:
∂t∂pt(x)=−div(ptut)(x)+2σt2Δpt(x)
第一项:
−div(ptut)(x)
表示确定性向量场 ut 对概率质量的搬运。
这一项和 ODE 的 continuity equation 完全一样。
它描述的是:
概率质量沿着向量场 ut 流动。
第二项:
2σt2Δpt(x)
表示随机噪声造成的扩散。
其中:
- Δ 是 Laplacian,可以理解为空间上的二阶导数;
- σt2 控制扩散强度;
- σt 越大,随机扩散越强。
所以:
−div(ptut)(x)
对应 transport,也就是“流动”。
而:
2σt2Δpt(x)
对应 diffusion,也就是“扩散”。
9.6 Laplacian Δpt(x) 直观上是什么?
在一维情况下,Laplacian 就是二阶导数:
Δpt(x)=∂x2∂2pt(x)
在高维情况下:
Δpt(x)=i=1∑d∂xi2∂2pt(x)
直观上,Laplacian 描述的是一个函数在空间中如何弯曲。
在 Fokker–Planck Equation 中:
Δpt(x)
描述的是概率密度如何因为随机噪声而向周围扩散。
随机噪声会让概率质量从高密度区域向周围低密度区域扩散,所以这一项和 heat equation 很像。
这也是为什么有时候会说:
Fokker–Planck Equation = continuity equation + heat equation。
其中:
- continuity equation 部分来自 drift;
- heat equation 部分来自 diffusion。
9.7 小结
Fokker–Planck Equation 描述的是 SDE 下概率密度的演化。
对于 SDE:
dXt=ut(Xt)dt+σtdWt
如果:
Xt∼pt
那么:
∂t∂pt(x)=−div(ptut)(x)+2σt2Δpt(x)
其中:
- −div(ptut)(x) 表示确定性向量场造成的概率质量流动;
- 2σt2Δpt(x) 表示随机噪声造成的概率扩散。
如果 σt=0,Fokker–Planck Equation 就退化成 continuity equation。
一句话总结:
Fokker–Planck Equation 是描述 SDE 如何改变整体概率分布的方程,它把 drift 引起的流动和 diffusion 引起的扩散统一到一个公式里。
10 SDE Extension Trick
10.1 定义
前面 Flow Model 里有一个目标向量场:
uttarget(x)
它满足:
dXt=uttarget(Xt)dt
如果:
X0∼p0
那么这个 ODE 会让样本分布沿着 probability path 走:
Xt∼pt
也就是说:
p0⟶pt⟶p1
这是一条确定性的路径。
现在我们希望把 ODE 改成 SDE,也就是加入随机噪声:
dXt=uttarget(Xt)dt+σtdWt
这里:
- uttarget(Xt)dt 是原来的确定性运动;
- σtdWt 是随机噪声项;
- σt 是 diffusion coefficient,用来控制噪声强度;
- Wt 是 Brownian motion / Wiener process。
但是问题来了:
如果只加随机噪声,分布会被额外扩散,原来的 pt 路径就会被破坏。
SDE extension trick 说:
不要只写成:
dXt=uttarget(Xt)dt+σtdWt
而是写成:
dXt=[uttarget(Xt)+2σt2∇xlogpt(Xt)]dt+σtdWt
这样仍然可以保证:
Xt∼pt
这里多出来的这一项:
2σt2∇xlogpt(Xt)
就叫 score correction。
10.2 公式
假设 uttarget(x) 是前面构造出来的 marginal vector field。
也就是说,ODE:
dXt=uttarget(Xt)dt
会让样本分布满足:
Xt∼pt
那么对于任意 diffusion coefficient:
σt≥0
我们可以构造下面这个 SDE:
dXt=[uttarget(Xt)+2σt2∇xlogpt(Xt)]dt+σtdWt
只要初始分布满足:
X0∼p0
那么这个 SDE 的边缘分布仍然满足:
Xt∼pt,0≤t≤1
这个 SDE 中一共有三部分。
第一部分是:
uttarget(Xt)
这是原本 Flow Model 的 marginal vector field。
它负责把样本整体从初始分布 p0 推向数据分布 p1。
第二部分是:
σtdWt
这是随机扩散项。
它会给样本运动加入随机扰动。
其中:
- Wt 是 Brownian motion;
- σt 是 diffusion coefficient;
- σt 越大,随机扰动越强。
第三部分是:
2σt2∇xlogpt(Xt)
这是 score correction,也就是 score 修正项。
其中:
∇xlogpt(Xt)
是 marginal score function。
它表示在当前分布 pt 下,概率密度上升最快的方向。
10.3 为什么这个公式成立?
这一点可以用 Fokker–Planck Equation 验证。
一般的 SDE 写作:
dXt=bt(Xt)dt+σtdWt
其中 bt(x) 是 drift。
它对应的 Fokker–Planck Equation 是:
∂t∂pt(x)=−div(ptbt)(x)+2σt2Δpt(x)
现在我们把 drift 设成:
bt(x)=uttarget(x)+2σt2∇xlogpt(x)
代入 Fokker–Planck Equation:
∂t∂pt(x)=−div(pt[uttarget+2σt2∇xlogpt])(x)+2σt2Δpt(x)
展开第一项:
∂t∂pt(x)=−div(ptuttarget)(x)−2σt2div(pt∇xlogpt)(x)+2σt2Δpt(x)
注意:
∇xlogpt(x)=pt(x)∇xpt(x)
所以:
pt(x)∇xlogpt(x)=∇xpt(x)
因此:
div(pt∇xlogpt)(x)=div(∇xpt)(x)=Δpt(x)
代回去:
∂t∂pt(x)=−div(ptuttarget)(x)−2σt2Δpt(x)+2σt2Δpt(x)
后两项正好抵消:
−2σt2Δpt(x)+2σt2Δpt(x)=0
所以最后只剩下:
∂t∂pt(x)=−div(ptuttarget)(x)
这正是原本 ODE 对应的 continuity equation。
也就是说,这个 SDE 和原来的 Flow ODE 会产生同一条 marginal probability path:
Xt∼pt
10.4 这个 trick 的核心意义
这个公式说明:
同一条 probability path pt,既可以由一个确定性的 ODE 生成,也可以由一族带随机噪声的 SDE 生成。
原来的 ODE 是:
dXt=uttarget(Xt)dt
扩展后的 SDE 是:
dXt=[uttarget(Xt)+2σt2∇xlogpt(Xt)]dt+σtdWt
其中 σt 可以控制随机性的大小。
如果:
σt=0
那么 SDE 退化成 ODE:
dXt=uttarget(Xt)dt
如果:
σt>0
那么生成过程会带有随机性,但由于加入了 score correction,边缘分布仍然是 pt。


如何训练生成式AI
该部分目标
对于 Flow Model,我们希望训练神经网络:
utθ(x)
让它逼近:
uttarget(x)
也就是:
utθ(x)≈uttarget(x)
对于 Diffusion Model,我们希望训练神经网络:
stθ(x)
让它逼近:
∇xlogpt(x)
也就是:
stθ(x)≈∇xlogpt(x)
Flow Matching
Flow Model 的采样
如果我们已经训练好了 vector field network:
utθ(x)
那么 Flow Model 的采样过程是:
X0∼pinit
然后解 ODE:
dtdXt=utθ(Xt)
最后返回:
X1
如果模型训练得好,那么:
X1∼pdata
实际计算时通常用 Euler method:
Xt+h=Xt+hutθ(Xt)
其中:
h=n1
n 是采样步数。
采样流程可以理解为:
- 从噪声分布中采样:
X0∼pinit
- 用神经网络预测当前位置的速度:
utθ(Xt)
- 沿着这个速度走一小步:
Xt+h=Xt+hutθ(Xt)
- 重复直到 t=1。
理想的 Flow Matching Loss
我们真正想学的是 marginal vector field:
uttarget(x)
所以最直接的 loss 是:
LFM(θ)=Et∼Unif[0,1], x∼pt[utθ(x)−uttarget(x)2]
这个 loss 的意思是:
在任意时间 t 和任意中间点 x,让神经网络预测的速度接近真实的 marginal vector field。
但是这个目标有一个问题:
uttarget(x)
通常不好直接计算。
因为它是 marginal vector field:
uttarget(x)=∫uttarget(x∣z)pt(x)pt(x∣z)pdata(z)dz
里面有对所有数据点 z 的积分。
所以直接训练:
utθ(x)≈uttarget(x)
不太现实。
虽然 marginal vector field 不好直接算,但是 conditional vector field 好算。
因此 Flow Matching 的想法是:
训练时不用 marginal target,而是使用 conditional target。
也就是训练:
utθ(x)≈uttarget(x∣z)
于是定义训练 loss:
LCFM(θ)=Ez∼pdata, t∼Unif[0,1], x∼pt(⋅∣z)[utθ(x)−uttarget(x∣z)2]
这叫 Conditional Flow Matching。
为什么用 conditional target 也能学到 marginal vector field?
训练时,我们采样:
z∼pdata
x∼pt(⋅∣z)
也就是说,训练数据中的 x 是通过某个隐藏的 z 生成出来的。
但是神经网络输入的是:
(x,t)
不是:
(x,t,z)
也就是说,网络不知道当前 x 到底来自哪个 z。
当同一个 x 可能来自多个不同的 z 时,网络为了最小化均方误差,最优预测会是这些 conditional vector field 的条件平均:
utθ(x)=E[uttarget(x∣z)∣x]
而第二讲已经证明:
E[uttarget(x∣z)∣x]=uttarget(x)
即
conditional target 的条件平均=marginal target
LCFM(θ)=LFM(θ)+C
所以,虽然训练时用的是 conditional target:
uttarget(x∣z)
但最优情况下,网络学到的是 marginal vector field:
uttarget(x)
这就是 marginalization trick 在训练中的作用。
Flow Matching 训练流程
Flow Matching 的训练算法如下。
给定:
z∼pdata
utθ(x)
每次训练:
- 从数据集中采样一个真实数据点:
z∼pdata
- 采样随机时间:
t∼Unif[0,1]
- 从 conditional probability path 中采样中间点:
x∼pt(⋅∣z)
- 计算 conditional vector field:
uttarget(x∣z)
- 计算 loss:
L(θ)=utθ(x)−uttarget(x∣z)2
- 用梯度下降更新参数 θ。
这就是 Flow Matching 的训练过程。
Gaussian Probability Path 下的 Flow Matching
常用的 Gaussian probability path 是:
pt(x∣z)=N(αtz,βt2Id)
等价采样形式是:
xt=αtz+βtϵ
其中:
ϵ∼N(0,Id)
对于这条 path,conditional vector field 是:
uttarget(x∣z)=(α˙t−βtβ˙tαt)z+βtβ˙tx
所以 Gaussian path 下的 Flow Matching loss 是:
LCFM(θ)=Et,z,ϵ[utθ(αtz+βtϵ)−uttarget(αtz+βtϵ∣z)2]
Straight Line Path 的特殊情况
一个非常直观的选择是 straight line path:
αt=t
βt=1−t
此时:
xt=tz+(1−t)ϵ
它表示从噪声 ϵ 到数据点 z 的直线插值。
当 t=0:
x0=ϵ
当 t=1:
x1=z
对时间求导:
dtdxt=z−ϵ
所以 conditional vector field 可以写成:
uttarget(xt∣z)=z−ϵ
也可以把 ϵ 消掉。
由:
x=tz+(1−t)ϵ
得到:
ϵ=1−tx−tz
代入:
z−ϵ=1−tz−x
所以:
uttarget(x∣z)=1−tz−x
Flow Matching 训练完成后怎么生成?
训练完成后,我们得到了:
utθ(x)
然后生成时不再需要数据点 z。
采样过程是:
- 从初始分布采样:
X0∼pinit
- 解 ODE:
dtdXt=utθ(Xt)
-
从 t=0 积分到 t=1。
-
返回:
X1
如果训练得好:
X1∼pdata
所以 Flow Matching 的完整逻辑是:
训练时用数据点 z 构造 conditional target;生成时只使用学到的 marginal vector field,从噪声走到数据。
Score Matching
Diffusion Model 为什么需要 Score?
第二讲里我们知道,Diffusion Model 需要 marginal score function:
∇xlogpt(x)
它表示当前分布 pt 中概率密度增加最快的方向。
从 SDE extension trick 可以看到,如果要用带噪声的 SDE 采样,需要:
dXt=[uttarget(Xt)+2σt2∇xlogpt(Xt)]dt+σtdWt
这里的∇xlogpt(Xt)就是 score function。
因此,Diffusion Model 需要训练一个 score network:
stθ(x)
让它逼近:
∇xlogpt(x)
也就是:
stθ(x)≈∇xlogpt(x)
Score Matching Loss(=Denoising Score Matching Loss)
最直接的训练目标是:
LSM(θ)=Et∼Unif[0,1], x∼pt[stθ(x)−∇xlogpt(x)2]
这个 loss 的意思是:
在任意时间 t 和任意中间点 x,让神经网络预测的 score 接近真实的 marginal score。
但是问题是:
∇xlogpt(x)
不好直接算。
因为:
pt(x)=∫pt(x∣z)pdata(z)dz
所以 marginal score 也涉及对所有数据点 z 的积分。
虽然 marginal score 不好算,但是 conditional score 好算。
也就是说:
∇xlogpt(x)不好算。但是:∇xlogpt(x∣z)通常可以算。
所以 Score Matching 的训练目标是:
LDSM(θ)=Ez,t,x[stθ(x)−∇xlogpt(x∣z)2]
其中:
z∼pdata
t∼Unif[0,1]
x∼pt(⋅∣z)
这就是 Denoising Score Matching。
为什么用 conditional score 能学到 marginal score?
原因和 Flow Matching 一样。
训练时,神经网络看到的是:
(x,t)
但它不知道当前 x 来自哪个 z。
对于固定的 x 和 t,最小化均方误差的最优预测是 conditional score 的条件期望:
stθ(x)=E[∇xlogpt(x∣z)∣x]
而第二讲已经得到:
E[∇xlogpt(x∣z)∣x]=∇xlogpt(x)
所以最优情况下:
stθ(x)=∇xlogpt(x)
也就是说:
虽然训练时使用 conditional score,但网络最终学到的是 marginal score。
Score Matching 训练流程
给定:
z∼pdata
stθ(x)
每次训练:
- 从数据集中采样真实数据点:
z∼pdata
- 采样随机时间:
t∼Unif[0,1]
- 从 conditional probability path 中采样中间点:
x∼pt(⋅∣z)
- 计算 conditional score:
∇xlogpt(x∣z)
- 计算 loss:
L(θ)=stθ(x)−∇xlogpt(x∣z)2
- 用梯度下降更新参数 θ。
Gaussian Path 下的 Conditional Score
对于 Gaussian probability path:
pt(x∣z)=N(αtz,βt2Id)
conditional score 有显式公式:
∇xlogpt(x∣z)=−βt2x−αtz
如果:
x=αtz+βtϵ
其中:
ϵ∼N(0,Id)
那么:
x−αtz=βtϵ
所以:
∇xlogpt(x∣z)=−βt2βtϵ=−βtϵ
因此 Gaussian path 下的 denoising score matching loss 是:
LDSM(θ)=Et,z,ϵ[stθ(αtz+βtϵ)+βtϵ2]
这里是加号,因为目标是:
stθ(x)≈−βtϵ
为什么叫 Denoising Score Matching?
因为训练时输入的:
xt=αtz+βtϵ
是一个被噪声污染的版本。
其中:
- z 是干净数据;
- ϵ 是噪声;
- βt 控制噪声强度。
score network 要学习:
stθ(xt)≈−βtϵ
也就是说,它要从 noisy sample 中推断噪声方向,或者推断如何往更高概率区域移动。
所以这个过程可以理解为:
给模型一个带噪声的样本,让它学习如何去噪。
这就是 denoising 的含义。
Noise Predictor 的写法
很多 diffusion model 不直接预测 score:
stθ(x)
而是预测噪声:
ϵtθ(x)
因为在 Gaussian path 下:
stθ(x)≈−βtϵ
所以可以定义:
ϵtθ(x)=−βtstθ(x)
这样训练目标可以改写成预测噪声:
ϵtθ(xt)≈ϵ
对应的 loss 是:
L(θ)=ϵtθ(xt)−ϵ2
这也是很多实际 diffusion model 训练时常见的形式。
低 βt 时的数值不稳定
在 Gaussian path 下,score target 是:
−βtϵ
如果:
βt
很小,那么:
βtϵ
会变得很大。
这会导致训练数值不稳定。
尤其在 t 接近 1 时,通常:
βt→0
所以这个 target 可能会爆炸。
这也是为什么实际 diffusion model 里经常会使用不同的参数化方式,例如预测噪声、预测 clean data,或者对 loss 加权。
Stochastic Sampling with Diffusion Models
SDE Extension Trick 回顾
第二讲里已经讲过 SDE extension trick。
如果:
uttarget(x)
是正确的 marginal vector field,并且:
∇xlogpt(x)
是正确的 marginal score function,那么对于任意 diffusion coefficient:
σt≥0
下面这个 SDE 仍然会让样本分布沿着 pt 走:
dXt=[uttarget(Xt)+2σt2∇xlogpt(Xt)]dt+σtdWt
也就是说:
Xt∼pt
Euler-Maruyama 采样
对于 SDE:
dXt=[utθ(Xt)+2σt2stθ(Xt)]dt+σtdWt
可以用 Euler-Maruyama method 离散化。
设步长为:
h=n1
则更新公式是:
Xt+h=Xt+h[utθ(Xt)+2σt2stθ(Xt)]+σthξ
其中:
ξ∼N(0,Id)
这里比 ODE 的 Euler method 多了一项随机噪声:
σthξ
如果:
σt=0
那么就退化成 Flow Model 的 ODE 采样:
Xt+h=Xt+hutθ(Xt)
Diffusion coefficient 的作用
在 SDE 采样公式中:
dXt=[utθ(Xt)+2σt2stθ(Xt)]dt+σtdWt
其中:
σt
是 diffusion coefficient。
它控制随机性的大小。
如果:
σt=0
那么采样是确定性的,等价于 Flow ODE。
如果:
σt>0
那么采样是随机的。
此时:
- σtdWt 会让样本随机扩散;
- 2σt2stθ(Xt) 会把样本往高概率区域拉回。
所以可以这样理解:
diffusion coefficient 控制“扩散得有多厉害”,score term 负责“把扩散后的样本拉回正确分布”。
Denoising Diffusion Models
定义
在这门课的框架里:
Denoising Diffusion Model = 使用 Gaussian probability path 的 Diffusion Model。
也就是使用:
pt(x∣z)=N(αtz,βt2Id)
作为 conditional probability path。
但在大部分情况下denoising diffusion model = diffusion model
DDM 的特殊性质:Score for Free
对于 Gaussian probability path,我们有两个公式。
第一个是 conditional vector field:
uttarget(x∣z)=(α˙t−βtβ˙tαt)z+βtβ˙tx
第二个是 conditional score:
∇xlogpt(x∣z)=−βt2x−αtz
这两个公式都有一个共同点:
它们都是 x 和 z 的线性组合。
因此,在 Gaussian path 下,conditional vector field 和 conditional score 可以互相转换。
意思是:
对 Denoising Diffusion Models 来说,不一定需要分别训练 vector field network 和 score network,因为二者可以通过公式互相转换。
Conditional 版本的转换公式
对于 Gaussian path,可以推导出:
uttarget(x∣z)=(βt2αtα˙t−β˙tβt)∇xlogpt(x∣z)+αtα˙tx
这个公式表示:
如果知道 conditional score,就可以得到 conditional vector field。
注意,这个公式里有:
αtα˙t
所以在 αt=0 的端点附近需要小心处理。
Marginal 版本的转换公式
对所有 z 做 marginalization 后,可以得到 marginal 版本:
uttarget(x)=(βt2αtα˙t−β˙tβt)∇xlogpt(x)+αtα˙tx
也就是说:
marginal vector field 可以由 marginal score function 转换得到。
如果我们训练的是 score network:
stθ(x)≈∇xlogpt(x)
那么可以得到一个 vector field network:
utθ(x)=(βt2αtα˙t−β˙tβt)stθ(x)+αtα˙tx
这说明:
在 DDM 中,训练 score network 后,也可以后处理得到 vector field network。
完整算法总结
Flow Matching 完整流程
训练阶段:
- 采样数据:
z∼pdata
- 采样时间:
t∼Unif[0,1]
- 采样中间点:
x∼pt(⋅∣z)
- 计算 conditional vector field:
uttarget(x∣z)
- 训练:
L(θ)=utθ(x)−uttarget(x∣z)2
采样阶段:
- 采样噪声:
X0∼pinit
- 解 ODE:
dXt=utθ(Xt)dt
- 返回:
X1
Score Matching 完整流程
训练阶段:
- 采样数据:
z∼pdata
- 采样时间:
t∼Unif[0,1]
- 采样中间点:
x∼pt(⋅∣z)
- 计算 conditional score:
∇xlogpt(x∣z)
- 训练:
L(θ)=stθ(x)−∇xlogpt(x∣z)2
对于 Gaussian path,可以写成:
xt=αtz+βtϵ
LDSM(θ)=stθ(xt)+βtϵ2
采样阶段:
- 采样噪声:
X0∼pinit
- 解 SDE:
dXt=[utθ(Xt)+2σt2stθ(Xt)]dt+σtdWt
- 返回:
X1
Flow Matching 和 Score Matching 的对比
| 方法 | 学什么 | 网络 | 训练 target | 采样方式 |
|---|
| Flow Matching | 速度场 | utθ(x) | uttarget(x∣z) | ODE |
| Score Matching | score function | stθ(x) | ∇xlogpt(x∣z) | SDE |
| DDM 特殊情况 | score 和 vector field 可互转 | stθ 或 utθ | Gaussian path 下的 target | ODE 或 SDE |
公式速查
Flow Matching Loss
LCFM(θ)=Ez,t,x[utθ(x)−uttarget(x∣z)2]
其中:
z∼pdata
t∼Unif[0,1]
x∼pt(⋅∣z)
Gaussian Path
xt=αtz+βtϵ
ϵ∼N(0,Id)
Gaussian Conditional Vector Field
uttarget(x∣z)=(α˙t−βtβ˙tαt)z+βtβ˙tx
Score Matching Loss
LDSM(θ)=Ez,t,x[stθ(x)−∇xlogpt(x∣z)2]
Gaussian Conditional Score
∇xlogpt(x∣z)=−βt2x−αtz
Gaussian Denoising Score Matching Loss
LDSM(θ)=Et,z,ϵ[stθ(αtz+βtϵ)+βtϵ2]
Stochastic Sampling SDE
dXt=[utθ(Xt)+2σt2stθ(Xt)]dt+σtdWt
DDM 中 score 到 vector field 的转换
utθ(x)=(βt2αtα˙t−β˙tβt)stθ(x)+αtα˙tx
构建图像生成器
这一讲从前几讲的「无条件生成」推进到「条件图像生成」。
前几讲主要讨论:
- 如何从简单分布
p_init 生成数据分布 p_data
- Flow model:
- 学习 vector field
- 通过 ODE 采样
- Diffusion model:
- 学习 score / vector field
- 通过 SDE 或 ODE 采样
- Flow Matching / Score Matching 的训练目标
- Gaussian probability path 下,score 和 vector field 可以互相转换
本讲重点:
- 将无条件生成扩展到条件生成
- 推导 classifier-free guidance, 简称 CFG
- 讨论图像生成中常见的网络结构:
- U-Net
- Diffusion Transformer, DiT
- Latent diffusion
- 简要介绍 Stable Diffusion 3 等大模型的结构思想
1. 从无条件生成到条件生成
1.1 无条件生成
无条件生成的目标是:
z∼pdata
也就是让模型生成一张「像真实数据」的图片。
例如:
Generate an image.
此时模型只需要学习整体数据分布:
pdata(z)
在 flow model 中,我们从简单分布采样:
X0∼pinit
然后模拟 ODE:
dXt=utθ(Xt)dt
最终希望:
X1∼pdata
1.2 条件生成 / Guided Generation
实际图像生成中,我们通常不只是想生成任意图片,而是想生成符合某个条件的图片。
例如:
Generate an image of a cat baking a cake.
这里的 prompt / label 记为:
y
目标变成从条件分布中采样:
z∼pdata(⋅∣y)
也就是说,我们希望模型生成的图片不仅真实,还要符合条件 y。
1.3 为什么这节课不用 conditional 这个词,而用 guided?
前面课程中已经使用了 conditional 这个词:
pt(x∣z)
这里的条件是数据点 z,表示 conditional probability path。
而本讲中的条件是 prompt / class label:
y
例如:
a dog running down a snowy hill
为了避免混淆,课程里把对 prompt / label 的条件生成称为:
guided generation
所以:
p_t(x | z) 里的 conditional:
- 指的是 probability path 以数据点
z 为条件
p_data(z | y) 里的 guided:
- 指的是生成结果受 prompt / label
y 引导
2. Guided Flow Model
2.1 无条件 flow model
无条件 flow model 的网络是:
utθ(x)
输入:
(x,t)
输出:
utθ(x)
表示在时间 t,位置 x 的速度。
采样时:
X0∼pinit
dXt=utθ(Xt)dt
目标:
X1∼pdata
2.2 有条件 / guided flow model
加入 prompt 或 label y 后,网络变成:
utθ(x∣y)
输入:
(x,t,y)
输出:
utθ(x∣y)
采样时固定一个条件 y:
X0∼pinit
dXt=utθ(Xt∣y)dt
目标:
X1∼pdata(⋅∣y)
也就是说,最终样本要符合 prompt / label。
3. Vanilla Guidance
3.1 最直接的想法
最自然的做法是:
训练时直接把 y 输入给网络。
数据集现在不是单独的图片:
z∼pdata
而是一对数据:
(z,y)∼pdata(z,y)
例如:
z = 一张图片
y = 这张图片对应的文本描述或类别标签
3.2 Guided CFM Objective
对于 guided flow matching,训练目标为:
LCFMguided(θ)=E(z,y),t,x[utθ(x∣y)−uttarget(x∣z)2]
其中:
(z,y)∼pdata(z,y)
t∼Unif[0,1]
x∼pt(⋅∣z)
注意这里 target 仍然是:
uttarget(x∣z)
不是:
uttarget(x∣y)
原因是:训练时我们仍然通过真实数据点 z 构造 probability path。
也就是说:
z 决定训练路径y 决定模型应该生成哪一类结果- 网络输入中加入
y
- target 仍然来自 conditional vector field
u_t^{target}(x|z)
3.3 Vanilla Guidance 的问题
理论上,如果模型足够强、数据足够好、训练足够充分,那么 vanilla guided model 应该可以学到:
pdata(⋅∣y)
但是实践中发现:
生成图像往往不够听 prompt 的话。
可能原因包括:
- 模型没有完全学好真实的 conditional distribution
- 数据中的图文配对本身有噪声
- prompt 与图像之间的语义关系复杂
- 模型生成质量和条件一致性之间存在 trade-off
于是我们希望在采样时人为加强条件 y 的作用。
这就是 guidance 的动机。
4. Classifier Guidance 的直觉
这一节的目标是解决一个问题:
如果我们想生成符合条件 y 的图片,例如 cat 或一句文本 prompt,应该怎么让生成过程更“听条件”?
无条件生成只需要让样本像真实图片;有条件生成不仅要真实,还要符合条件 y。
所以我们希望生成方向可以分成两部分:
有条件生成方向=让图片真实的方向+让图片符合条件 y 的方向
4.1 Gaussian path 下 vector field 和 score 的关系
在 Gaussian probability path 下,有一个重要关系:
uttarget(x∣y)=atx+bt∇xlogpt(x∣y)
其中:
at=αtα˙t
bt=βt2(αtα˙t−βtβ˙t)
这里的 at 和 bt 只和 noise schedule 有关,也就是只和 αt,βt 的选择有关。
这个公式的意思是:
在 Gaussian path 下,Flow Matching 里的 vector field 可以用 Diffusion 里的 score 表示。
其中:
∇xlogpt(x∣y)
是 guided score。
它表示:
在给定条件 y 的情况下,当前点 x 应该往哪个方向移动,才会更像条件分布里的样本。
比如 y = cat,那么它大致表示:
当前 noisy image 应该怎么变,才能更像一张猫图。
4.2 用 Bayes rule 拆 guided score
根据 Bayes rule:
pt(x∣y)=pt(y)pt(x)pt(y∣x)
两边取 log:
logpt(x∣y)=logpt(x)+logpt(y∣x)−logpt(y)
对 x 求梯度:
∇xlogpt(x∣y)=∇xlogpt(x)+∇xlogpt(y∣x)−∇xlogpt(y)
因为 pt(y) 只和条件 y 有关,和当前变量 x 无关,所以:
∇xlogpt(y)=0
因此:
∇xlogpt(x∣y)=∇xlogpt(x)+∇xlogpt(y∣x)
也就是:
guided score=unguided score+classifier gradient
有条件的方向=让图片真实的方向+让图片符合 y 的方向
其中:
∇xlogpt(x)
表示:
怎么让当前样本更像真实图片。
而:
∇xlogpt(y∣x)
表示:
怎么改变当前样本,才能让它更符合条件 y。
比如 y = cat,那么:
∇xlogpt(y∣x)
可以理解成:
怎么调整当前 noisy image,才能让分类器更相信它是一只猫。
前面有:
uttarget(x∣y)=atx+bt∇xlogpt(x∣y)
又有:
∇xlogpt(x∣y)=∇xlogpt(x)+∇xlogpt(y∣x)
代入可得:
uttarget(x∣y)=atx+bt[∇xlogpt(x)+∇xlogpt(y∣x)]
展开:
uttarget(x∣y)=atx+bt∇xlogpt(x)+bt∇xlogpt(y∣x)
其中:
atx+bt∇xlogpt(x)
就是无条件 vector field:
uttarget(x)
所以得到:
uttarget(x∣y)=uttarget(x)+bt∇xlogpt(y∣x)
这个式子是 classifier guidance 的核心。
它的意思是:
有条件生成方向=无条件生成方向(让图片变得真实)+条件引导方向(让图片更符合条件)
4.3 Classifier Guidance
如果觉得模型生成的结果不够符合条件 y,可以把条件引导方向放大。
引入 guidance scale:
w>1
然后定义新的 guided vector field:
u~t(x∣y)=uttarget(x)+wbt∇xlogpt(y∣x)
直觉上:
原本的 uttarget(x) 负责让图像像真实图片;
额外的 ∇xlogpt(y∣x) 负责把图像往条件 y 的方向推;
w 控制这个“往条件靠近”的力度。
当:
w=1
就是正常的 conditional generation。
当:
w>1
条件引导被加强,模型会更重视 prompt / label。
但 w 不是越大越好:
w 较小:图像更自然、多样性更高,但可能不太听 promptw 较大:图像更符合 prompt,但多样性可能下降w 过大:可能导致图像不自然、过饱和或出现伪影
所以 w 是一个 trade-off:
prompt adherencevs.quality / diversity
4.4 Classifier Guidance 的问题
Classifier guidance 需要额外训练一个 classifier:
pt(y∣x)
并且在采样时还要计算:
∇xlogpt(y∣x)
这会带来几个问题:
- 需要额外训练一个 classifier
- classifier 要能处理 noisy image xt
- 如果 y 是文本 prompt,而不是简单类别,pt(y∣x) 很难建模
- 采样时要对 classifier 求梯度,计算更复杂
因此,后来更常用的是 Classifier-Free Guidance,也就是 CFG。
5. Classifier-Free Guidance, CFG
Classifier-Free Guidance 的目标是:
不额外训练 classifier,也能加强条件 y 对生成结果的影响。
它的核心想法是:
用 conditional model 和 unconditional model 的差值,来表示条件 y 带来的额外方向。
5.1 conditional 和 unconditional 输出
同一个网络要同时支持两种输入方式。
有条件输入:
utθ(x∣y)
表示:
给定条件 y 时,模型认为当前样本应该往哪里走。
无条件输入:
utθ(x∣∅)
表示:
不给任何条件时,模型认为当前样本应该往哪里走。
其中:
∅
表示空条件,也就是 unconditional generation。
5.2 为什么二者的差值可以表示条件方向?
前面已经得到:
uttarget(x∣y)=uttarget(x)+bt∇xlogpt(y∣x)
把无条件项移到左边:
uttarget(x∣y)−uttarget(x)=bt∇xlogpt(y∣x)
这说明:
有条件生成方向−无条件生成方向=条件引导方向
也就是说:
- 无条件方向负责生成真实图片
- 有条件方向负责生成符合
y 的真实图片
- 两者的差值就是条件
y 额外带来的影响
所以不一定需要显式计算:
∇xlogpt(y∣x)
可以用:
utθ(x∣y)−utθ(x∣∅)
来近似这个条件引导方向。
5.3 从 Classifier Guidance 推到 CFG
Classifier guidance 的形式是:
u~t(x∣y)=uttarget(x)+wbt∇xlogpt(y∣x)
而前面有:
bt∇xlogpt(y∣x)=uttarget(x∣y)−uttarget(x)
代入:
u~t(x∣y)=uttarget(x)+w[uttarget(x∣y)−uttarget(x)]
展开:
u~t(x∣y)=uttarget(x)+wuttarget(x∣y)−wuttarget(x)
整理:
u~t(x∣y)=(1−w)uttarget(x)+wuttarget(x∣y)
把无条件生成写成空条件形式:
uttarget(x)=uttarget(x∣∅)
于是:
u~t(x∣y)=(1−w)uttarget(x∣∅)+wuttarget(x∣y)
实际使用神经网络近似:
u~tθ(x∣y)=(1−w)utθ(x∣∅)+wutθ(x∣y)
这就是 CFG 的核心公式。
5.4 CFG 的另一种等价写法
CFG 公式也常写成:
u~tθ(x∣y)=utθ(x∣∅)+w[utθ(x∣y)−utθ(x∣∅)]
这个写法更容易理解。
其中:
utθ(x∣∅)
是无条件方向,负责保证生成结果像真实图片。
而:
utθ(x∣y)−utθ(x∣∅)
是条件方向,表示条件 y 额外带来的影响。
乘上 w:
w[utθ(x∣y)−utθ(x∣∅)]
就是把条件方向放大。
所以 CFG 可以理解成:
最终生成方向=无条件方向+w×条件方向
5.5 CFG 的采样过程
假设我们已经训练好了一个 guided vector field:
utθ(x∣y)
生成时需要做以下几步:
- 选择一个 prompt / label:
比如:
y=a cat baking a cake
如果想做无条件生成,就令:
y=∅
- 选择 guidance scale:
w>1
w 控制模型有多听条件。
- 从初始噪声分布采样:
X0∼pinit
通常:
pinit=N(0,I)
- 用 CFG 后的 vector field 进行 ODE 采样:
dXt=[(1−w)utθ(Xt∣∅)+wutθ(Xt∣y)]dt
从:
t=0
积分到:
t=1
最终得到生成结果:
X1
5.6 CFG 的直觉
CFG 每一步采样时,相当于问模型两个问题。
第一个问题:
如果不给 prompt,你觉得当前样本应该往哪里走?
得到:
utθ(x∣∅)
第二个问题:
如果给定 prompt / label y,你觉得当前样本应该往哪里走?
得到:
utθ(x∣y)
然后二者相减:
utθ(x∣y)−utθ(x∣∅)
这个差值表示:
条件 y 额外带来的方向。
最后把这个方向放大 w 倍,再加回无条件方向:
u~tθ(x∣y)=utθ(x∣∅)+w[utθ(x∣y)−utθ(x∣∅)]
所以 CFG 的大白话是:
先保证图片像真实图片,再把它往 prompt 的方向多推一点。
5.7 为什么叫 classifier-free?
因为它实现了类似 classifier guidance 的效果:
增强条件 y 对生成结果的影响
但是它不需要额外训练 classifier:
pt(y∣x)
也不需要显式计算:
∇xlogpt(y∣x)
它只需要一个同时支持 conditional 和 unconditional 的生成模型。
所以叫:
Classifier-Free Guidance
6. 为什么图像生成不能简单用 MLP?
一张图片可以表示为:
x∈RCimage×H×W
例如 RGB 图片:
Cimage=3
图片具有空间结构:
- 邻近像素高度相关
- 局部纹理重要
- 不同尺度的信息都重要
- 物体结构具有层次性
- prompt 信息需要影响全局和局部内容
因此,普通 MLP 不适合直接处理高分辨率图像。
需要更合适的架构。
课程中主要讨论两类:
- U-Net
- Diffusion Transformer, DiT
7. U-Net 架构
U-Net 是早期 diffusion models 中非常常见的结构。
它由三部分组成:
- Encoder
- Middle block / Midcoder
- Decoder
并且有 skip connections / residual connections。
大致结构:
x_t
|
Encoder
|
Encoder
|
...
|
Middle
|
Decoder
|
Decoder
|
output velocity / score / noise
同时 encoder 的中间特征会通过 skip connection 传给 decoder。
7.1 U-Net 为什么适合图像生成?
U-Net 的优点:
- 卷积结构适合处理图像局部特征
- Encoder 逐步下采样,捕捉大尺度语义
- Decoder 逐步上采样,恢复空间细节
- Skip connection 保留高分辨率局部信息
- 时间
t 和条件 y 可以通过 embedding 注入到各层
7.2 Lab Three U-Net
课程 Lab 3 中使用一个简化版 U-Net 来做 MNIST 条件生成。
输入:
xt∈R1×32×32
条件:
y∈{0,1,…,9,∅}
也就是:
网络输入包括:
noisy image x_t
time t
label y
网络输出:
utθ(xt∣y)
也就是当前 noisy image 的 vector field / velocity prediction。
7.3 时间和条件怎么进入 U-Net?
时间 t 和 label y 通常先经过 embedding:
t -> time embedding
y -> label embedding
然后这些 embedding 会被注入到网络的不同层中。
常见方式包括:
- 加到 feature map 上
- 用 MLP 变换后调制 feature
- 用 normalization 的 scale / shift 参数调制
- 在 attention 层中作为条件信息
条件信息怎么进入网络,是图像生成模型设计的关键。
8.1 DiT 的核心想法
Diffusion Transformer 的核心思想是:
把图像切成 patches,然后在 patch tokens 之间做 attention。
这来自 Vision Transformer, ViT。
图像不再只被卷积处理,而是被转成 token 序列:
image / latent -> patches -> patch embeddings -> transformer blocks
8.2 DiT 的基本流程
大致流程:
noisy image or noisy latent
|
patchify
|
linear projection
|
add position embedding
|
add time / label conditioning
|
DiT blocks
|
linear projection
|
unpatchify
|
output
其中每个 patch 类似 NLP 里的 token。
Transformer 用 self-attention 建模 patch 之间的全局关系。
8.3 DiT 相比 U-Net 的特点
U-Net:
convolution based
擅长局部建模、层次化特征、多尺度结构。
DiT:
attention based
擅长全局建模、scaling、统一 token 表示。
现代大规模图像生成模型越来越多采用 Transformer 或 Transformer-like 架构,因为它们更适合大规模训练和多模态条件输入。
9. Latent Diffusion
9.1 为什么要在 latent space 里生成?
直接在 pixel space 里做 diffusion / flow matching 计算量很大。
例如高分辨率图片:
x∈R3×H×W
维度很高。
Latent diffusion 的想法是:
先用一个预训练 autoencoder 把图像压缩到 latent space,
然后在 latent space 里训练生成模型。
9.2 Latent diffusion 的结构
先训练或使用一个预训练 autoencoder:
Encoder:
E(x)=z
Decoder:
D(z)=x^
生成模型不直接在图片 x 上运行,而是在 latent z 上运行:
pixel image x
|
encoder E
|
latent z
|
diffusion / flow model in latent space
|
generated latent
|
decoder D
|
generated image
9.3 Latent space 的优点
- 降低计算成本
- 降低空间维度
- 可以训练更大的生成模型
- 更适合高分辨率生成
- autoencoder 负责像素级压缩和重建
- diffusion / flow model 负责语义生成和结构建模
Stable Diffusion 系列就是 latent diffusion 的代表。
10. Stable Diffusion 3 Case Study
10.1 Stable Diffusion 3 的几个关键思想
Stable Diffusion 3 结合了多个现代图像生成技术:
- 使用预训练 autoencoder
- 在 latent space 中建模
- 使用 CLIP text embedding
- 使用 T5-XXL text embedding
- 使用 cross-attention 处理文本条件
- 使用类似 DiT 的 transformer 架构
- 从 class-conditioning 扩展到 text-conditioning
- 使用 rectified flow / flow matching 相关训练目标
- CLIP embedding:
- T5-XXL embedding:
两者结合可以让模型更好理解 prompt。
10.2 Cross-Attention 的作用
在 text-to-image 生成中,模型需要让图像特征关注文本信息。
Cross-attention 做的是:
image / latent tokens attend to text tokens
或者更一般地说:
用文本条件调制图像生成过程。
这样 prompt 中的词语、语义关系、属性、物体等信息可以影响图像内容。
Generative Robotics
如果生成对象不是图片,而是机器人动作,flow / diffusion model 可以怎么用?
Robotics 里的生成问题是什么?
图像生成里,我们通常是:
condition→image
比如:
"a cat baking a cake"→一张图片
而 robotics 里,我们想要的是:
observation+task→action
也就是:
(ot,y)→at
其中:
- ot:机器人当前看到的东西,比如相机图像、关节角度、夹爪状态
- y:任务条件,比如语言指令 “pick up the cup”
- at:机器人接下来要执行的动作,比如机械臂末端移动、夹爪开合
所以机器人策略可以写成:
π(at∣ot,y)
意思是:
给定当前观察和任务,机器人应该采取什么动作?

为什么机器人策略可以看成生成模型?
普通分类任务是输出一个类别。
但机器人动作不是一个简单类别,而是连续的、高维的,并且可能有很多合理答案。
例如任务是:
把杯子拿起来。
机器人可能有很多种做法:
- 从左边接近杯子
- 从右边接近杯子
- 先调整手腕角度
- 先靠近再夹取
- 直接抓杯身
- 抓杯柄
这些动作都可能是合理的。
所以对于同一个观察 ot 和任务 y,动作分布可能是多峰的:
p(at∣ot,y)
这里不是只有一个正确答案,而是有一整个动作分布。
因此,机器人策略很适合用生成模型来建模:
at∼pθ(at∣ot,y)
也就是说:
机器人不是只预测一个平均动作,而是从可能的动作分布里采样一个动作。
为什么简单的 MSE 行为克隆不够好?
最直接的 imitation learning 是 behavior cloning。
数据集里有很多人类或专家演示:
(ot,at)
然后训练一个网络:
aθ(ot)
让它预测专家动作:
L(θ)=E[∥aθ(ot)−at∥2]
这个方法的问题是:
MSE 会倾向于预测平均值。
如果同一个状态下有两种合理动作:
那么 MSE 可能学出一个中间动作。
但中间动作可能并不是合理动作。
比如:
- 左边绕可以
- 右边绕可以
- 但是往正中间走会撞上障碍物
这就是多模态动作分布的问题。
所以机器人策略不能总是学“平均动作”,而应该能表达:
p(at∣ot,y)
也就是多个可能动作的分布。
Diffusion Policy 的核心思想
Diffusion Policy 的想法是:
不直接预测一个动作,而是用 diffusion model 生成一段动作序列。
也就是说,它把机器人动作当成要生成的对象。
图像 diffusion 是生成图片:
ϵ→x
机器人 diffusion policy 是生成动作序列:
ϵ→A
其中:
A=(at,at+1,...,at+H−1)
表示未来一段时间的动作序列,也叫 action chunk 或 action horizon。
所以模型学习的是:
pθ(A∣ot,y)
意思是:
给定当前观察和任务,生成未来一段动作。
如果模型只预测下一步动作:
at
那么机器人每一步都要重新决定,很容易出现抖动或不连贯。
如果模型一次生成未来一段动作:
A=(at,at+1,...,at+H−1)
那么它可以提前规划一小段轨迹。
这样有几个好处:
- 动作更平滑
- 能表达短期计划
- 对接触丰富的任务更稳定
- 可以减少一步一步贪心决策带来的错误
但机器人又不能完全开环执行太长时间。
因为现实环境会变化,动作执行也会有误差。
所以通常使用以下做法:
- 当前时刻观察环境:
ot
- 模型生成未来 H 步动作:
At=(at,at+1,...,at+H−1)
- 只执行前面几步,比如前 K 步:
at,...,at+K−1
- 然后重新观察环境,再生成新的动作序列。
也就是说:
模型会规划一小段未来,但不会盲目执行完整计划,而是不断重新观察、重新规划。
这对机器人很重要,因为机器人是在真实世界里闭环控制。
Diffusion Policy 的训练方式
训练数据是一批专家演示:
(ot,y,At)
其中:
- ot 是当前观察
- y 是任务条件,可以是语言、类别或目标
- At 是专家接下来一段时间的动作序列
Diffusion Policy 在动作空间里加噪:
Ak=αkA0+βkϵ
其中:
- A0 是真实动作序列
- Ak 是加噪后的动作序列
- ϵ∼N(0,I)
- k 是 diffusion step
训练目标可以是预测噪声:
ϵθ(Ak,k,ot,y)≈ϵ
也可以等价地预测 denoised action 或 vector field。
diffusion 不是在图片空间里去噪,而是在动作序列空间里去噪。
Diffusion Policy 的采样过程
推理时,机器人没有专家动作。
所以从随机噪声动作开始:
AK∼N(0,I)
然后模型根据当前观察和任务逐步去噪:
AK→AK−1→⋯→A0
最终得到一段动作序列:
A0=(at,at+1,...,at+H−1)
然后机器人执行前几步,再重新观察、重新规划。
直觉上:
Diffusion Policy 是在“想象一段合理的未来动作”,然后不断修正这段动作,直到它变成可执行的轨迹。
为什么 diffusion 适合机器人动作?
Diffusion model 在机器人里有几个优势。
1 可以表达多模态动作
同一个任务可能有多种合理做法。
Diffusion 不一定输出平均动作,而是可以从动作分布中采样。
所以它更适合:
p(A∣ot,y)
这种多峰分布。
2 适合高维连续动作
机器人动作通常是连续值,比如:
- 机械臂关节角
- 末端执行器位姿
- 夹爪开合
- 双臂协作动作
这些动作不是离散 token,而是连续向量。
Diffusion / flow model 本来就适合连续空间建模。
3 训练比较稳定
相比一些强化学习方法,behavior cloning + diffusion 的训练更接近监督学习。
训练数据来自专家演示,目标是学习动作分布。
这通常比直接从真实机器人上做 RL 更安全、更稳定。
4 可以生成平滑的动作序列
因为模型一次生成一段动作,而不是只预测下一步,所以动作更容易保持连续和平滑。
这对真实机器人很重要。
Large Behavior Models, LBM
Large Behavior Models 可以理解成机器人领域的“大行为模型”。
它的目标类似于 LLM,但对象不同。
LLM 学的是:
p(text token∣context)
LBM 学的是:
p(action∣robot observation,task)
也就是:
给定机器人看到的世界和任务,生成机器人应该执行的行为。
LBM 的输入可能包括:
- 相机图像
- 机器人 proprioception,比如关节角、末端位姿、夹爪状态
- 语言任务
- 历史观察
- 历史动作
输出通常是:
- 未来动作序列
- 末端执行器轨迹
- 关节控制指令
- 夹爪动作
普通机器人策略通常是针对一个任务训练的。
比如:
这种策略是 specialist。
而 LBM 希望成为 generalist。
它在很多任务、很多场景、很多数据上训练,希望学到更通用的行为能力。
对比一下:
| 单任务策略 | Large Behavior Model |
|---|
| 只学一个任务 | 学很多任务 |
| 数据规模较小 | 数据规模更大 |
| 泛化能力有限 | 目标是更强泛化 |
| 通常不需要语言 | 常常使用语言作为任务条件 |
| 更像专用工具 | 更像机器人基础模型 |
为什么 robotics 需要 scale?
在语言模型中,scale 很重要:
机器人领域也希望出现类似现象:
当模型在更多机器人数据、更丰富任务上预训练后,它能更快学会新任务,也能在真实世界中更鲁棒。
LBM 的核心想法就是:
通过多任务、多场景、多数据源训练,让机器人策略学到通用的行为先验。
这个行为先验可以帮助机器人:
- 更快适应新任务
- 用更少的新数据完成 fine-tuning
- 在环境变化时更稳定
- 学到一些跨任务共享的操作模式
模型评估
机器人策略的评估通常关注:
- 成功率
- 鲁棒性
- 泛化能力
- 执行稳定性
- 对新物体、新场景、新任务的适应能力
- 是否能从少量新数据中快速 fine-tune
- 在真实机器人上的表现
特别重要的是:
训练 loss 低,不一定代表真实机器人执行成功率高。
因为真实世界存在:
- 传感器噪声
- 控制误差
- 未见过的物体
- 接触不确定性
- 环境变化
所以 robotics 更看重真实 rollout 的结果。
Diffusion Policy 的优势和局限
1 优势
Diffusion Policy 的优势:
- 能建模多模态动作分布
- 适合连续高维动作
- 可以生成动作序列
- 动作更平滑
- 训练方式接近监督学习
- 在复杂 manipulation task 上效果好
2 局限
Diffusion Policy 也有问题:
- 采样需要多步 denoising,可能比较慢
- 真实机器人需要实时控制
- 对数据质量和覆盖范围要求高
- 如果观察分布偏离训练数据,可能失败
- 长期任务还需要更强的规划能力
- 只靠 imitation learning 很难超过演示数据质量
所以后续研究会关注:
- 更快采样
- flow matching action generation
- 更大规模多任务数据
- 更强视觉语言理解
- RL fine-tuning
- world model
- hierarchical planning

